Opis
Knowikis cases
Build sample knowledge wikis/cases on different implementations. Consider
Prezentacja
Sprawozdanie
Wstęp
Tematem tego opracowania są rozwijające się obecnie projekty starające się wcielić w życie idee sieci semantycznej i web 3.0. Wszystkie opierają się na zasadzie istnienia tzw. meta-danych z wyjątkiem właściwych informacji widocznych dla użytkownika strony. Meta-dane pozwalają łączyć i grupować informacje o podobnej tematyce, identyfikować faktyczne znaczenie informacji i przeprowadzać wnioskowanie.
Za zadanie mamy uruchomić i przetestować wprowadzając przykładowe dane i meta-dane najważniejsze projekty z zakresu Semantic-Web. Zaliczają się do nich:
Semantic MediaWiki która jest faktycznie rozszerzeniem samego MediaWiki czyli systemu na którym oparta jest np. wikipedia.
IKE Wiki – projekt który został przerwany a za jego kontynuacje przyjmuje się KIWI, którym to zajmiemy się w niniejszym sprawozdaniu.
KIWI – rozbudowany projekt o wysokim budżecie odróżniający się od Semantic MediaWiki zorientowaniem konkretnie na tematykę Semantic Web. Jest to projekt tworzony od podstaw z myślą o sieci semantycznej.
SweetWiki - projekt dedykowany sieci semantycznej tworzony w Javie.
Sposób testowania
SMW (Semantic MediaWiki) będziemy testować wprowadzając przykładowe dane. Na ich podstawie będziemy prezentować możliwości w zakresie sieci semantycznej. Tematem przykładowych danych będzie motoryzacja a w szczególności samochody z podziałem na marki i rodzaje.
Temat został wybrany z uwagi na istnienie licznych powiązań oraz zależności między modelami, markami i rodzajami samochodów. Auta posiadają też liczne parametry które jako składniki properties (właściwości) również pozwolą odpowiednio zaprezentować mechanizmy sieci semantycznej.
Pozostałe dwa projekty (KIWI oraz SweetWiki) zważywszy na brak możliwości przeprowadzenia miarodajnych testów zostaną opisane od strony teoretycznej wraz z najważniejszymi metodami operowania na metadanych.
Projekty Semantic Web
Z początku zajmiemy systemem istniejącym na bazie MediaWiki.
Opis i Wymagania
Semantic MediaWiki wykonane jest podobnie jak samo MediaWiki przy pomocy języka PHP i w oparciu o jeden z systemów baz danych – mySQL bądź PostgreSQL. Instalacja polega na dograniu do już zainstalowanej wersji MediaWiki odpowiedniego katalogu i załączeniu w pliku konfiguracyjnym nowego rozszerzenia.
Mimo, że aplikacja posiada możliwość wczytywania odpowiednich meta-danych i szablonów bezpośrednio z poziomu uproszczonego kodu, stworzone zostały liczne rozszerzania mające na celu nam ten proces ułatwić. W prezentacji tego projektu użyto rozszerzeń takich jak SemanticForms pozwalających na wprowadzanie informacji wraz z meta-danymi na podstawie wcześniej zdefiniowanych szablonów i formularzy oraz Semantic Query Form Tool do wspomagania tworzenia zapytań wyszukujących informacje.
Wprowadzanie i wyszukiwanie danych
Przy wprowadzaniu danych posiłkowano się rozszerzeniami a najbardziej pomocne z nich okazało się Semantic Forms. Każda podstrona była tworzona na podstawie następujących struktur:
właściwość (property)
szablon (template)
formularz (form)
kategoria (category)
Wszystkie z powyższych można jednocześnie założyć i skonfigurować zakładając klasę (class). Można to też robić pojedynczo łącząc poszczególne struktury przy założeniach, że klasa jest nadrzędną grupą. Formularz służy do szybkiego zakładania i edycji stron na podstawie zdefiniowanych szablonów (templates). Szablony te z kolei służą grupowaniu właściwości (properties), które są w Semantic MediaWiki podstawową jednostką informacji.
Opisana powyżej struktura została utworzona i wypełniona przykładowymi danymi. Efekty zaprezentowane są na podstronie głównej zainstalowanej kopii Semantic MediaWiki:
Semantic MediaWiki posiada system zapytań (inline queries) umożliwiających filtrowanie i wypisywanie wyników wyszukań zgodnie z zadanym zapytaniem.
Wyniki zwracane przez inline queries są filtrowane na podstawie odpowiednich właściwości. Utworzone w ten sposób tabele są automatycznie aktualizowane przy zmianie dotyczących ich podstron i właściwości. Ponadto przy dodaniu dużej ilości meta-danych, możliwości wyszukiwania i listowania konkretnych pozycji są bardzo szerokie.
Przykładowy efekt działania inline query jest zaprezentowany poniżej:
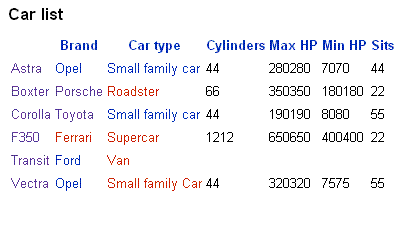
Jak widzimy możemy nie tylko odczytać interesujące informacje ale także po kliknięciu linka zostaniemy przeniesieni do szczegółów wskazanej podstrony, kategorii czy nawet właściwości. Tworzymy więc rozbudowaną strukturę ściśle powiązaną określonymi założeniami co pozwala w bardzo dużym stopniu uporządkować wprowadzane dane.
W powyższej tabeli widać, że liczbowe metadane (properties) są wyświetlane ze zdublowaniem. Wystąpił więc błąd związany prawdopodobnie z błędem systemu lub samej jego instalacji.
W podobny sposób możemy zadawać pytania w specjalnym formularzu który wykorzystuje składnie znaną z inline queries. Dla końcowego użytkownika systemu wykorzystywanie tego mechanizmu byłoby skomplikowane i wymagałoby zapoznania się i przyswojenia odpowiedniej składni. Dlatego też powstały rozszerzenia jak np. Halo Extension, które oferują możliwość wykreowania przyjaznego użytkownikowi interfejsu do przeprowadzania wyszukań.
SweetWiki
Jest to system rozwijany do 2007 roku posiadający zaawansowaną funkcjonalność sieci semantycznej. Zbudowany jest w oparciu o JavaServerPages, był testowany na serwerze tomcat 5.5. Wszystkie strony zapisywane są w formacie XHTML lub JSP/JSPX.
System używa RDF do zapisu wszelkich meta danych. Jego rozszerzenie czyli OWL pozwala natomiast na tworzenie ontologii umożliwiających działanie sieci semantycznej i mechanizmów wnioskowania.
O roku 2007 kiedy wypuszczona została wersja beta tego systemu nie są udostępniane żadne odsłony tego systemu. Nie będziemy więc szerzej opisywać tego systemu w tym sprawozdaniu, przyjmując, że projekt jest zawieszony.
KIWI
Projekt ten był od samych podstaw tworzony z myślą o sieci semantycznej. Dlatego występują znaczne różnice między nim a opisywanym wcześniej SMW, który rozbudowuje istniejące systemy wiki. Na stronach projektu KIWI udostępniono paczki do wygodnej instalacji oprogramowania na własnym komputerze. Po uruchomieniu skryptu instalowana jest baza danych JBOSS oraz cała aplikacja.
Mimo, że instalacja wydaje się bardzo prosta to często występują bardzo kłopotliwe błedy. Z naszej perspektywy najbardziej dokuczliwy jest ten, który ogranicza możliwość instalacji na systemach z ustawionym językiem polskim. Tylko pierwsza odsłona aplikacji jest wolna od tego błędu, co w efekcie ogranicza nas do najmniej zaawansowanej wersji oprogramowania.
Wszystkie wersje, łącznie z najnowszymi, niedawno udostępnionymi, nie są wolne od błędów co nie pozwoliło na miarodajne, wygodne testy. Poniżej opiszemy jednak budowę, wygląd oraz zasadę działania systemu.
Struktura KIWI
Kiwi składa się z pięciu działów służących do zarządzania treścią i meta-danymi oraz administracją swoim profilem i serwisem.
Pierwszą i najważniejszą częścią z punktu widzenia samej zawartości jest Wiki, które służy do dodawania nowych podstron i dopisywania tagów tworzących meta-dane. Samo dodawanie tagów i relacji RDF działa, lecz wszystko jest na razie zrobione bardzo mało intuicyjnie i w ograniczonym zakresie. Można wnioskować, że jest to wina wersji beta i zostanie uproszczone w przyszłych wersjach i uczynione przyjaznym dla użytkownika.
Drugą częścią jest Browse location czyli dział przeznaczony do tagowania pojęć i miejsc w oparciu o mapę google maps.
Kolejnymi częściami nastawionymi już raczej na administrację serwisem jest Inpector (przeglądanie meta-danych), Admin (konfiguracja serwisem) oraz My Universe (zarządzanie profilem).
Zasada działania
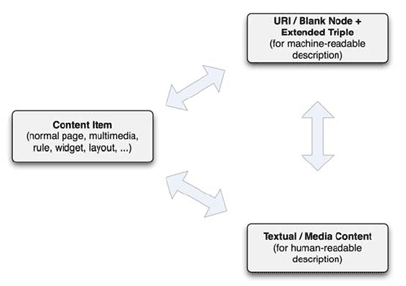
Koncepcja wiki opiera się na współdziałaniu trzech elementów:
Content Items - tzw. „jednostki wiedzy”, które są faktycznymi stronami i elementami systemu.
Taggs & Annotations -
URI wraz z adnotacją RDF.
User interface - teksty i dane multimedialne widoczne dla użytkownika.
Zasada działania polega na przyporządkowaniu elementów Content Items do określonego URI z którym z kolei powiązane są meta-dane w konwencji RDF. Należy przy tym zaznaczyć, że występują powiązania 1:1 między jednostkami wiedzy a URI co pozwala na jednoznaczne adresowanie. Elementy KIWI są więc jednoznacznie określone, posiadają przyporządkowane do nich meta-dane oraz dane przeznaczone do wyświetlania i odczytywania przez użytkowników.
Podsumowanie
Opisywane tutaj systemy są zróżnicowane leczy wszystkie opierają się na koncepcji wyposażania danych na stronach w meta-dane, które mogą być rozpoznawane i kojarzone przez maszynę (wyszukiwarkę). Jak widać z porównywanych systemów jak na razie tylko SMW (Semantic MediaWiki) jest w na tyle zaawansowanym stadium, żeby można było mówić o wykorzystywaniu go praktyce.
SMW nie jest systemem budowanym od podstaw z myślą o SemanticWeb a jedynie rozszerzeniem MediaWiki. Oznacza to jednak, że oparty jest na bardzo popularnej platformie co daje mu sporą przewagę nad konkurencją.
KIWI a wcześniej IKEWiki to rozbudowywany już od dłuższego czasu system przeznaczony konkretnie do współdziałania z koncepcją SemanticWeb. Stale dochodzi do publikacji kolejnych odsłon BETA-wersji, jednak jak mogliśmy zauważyć daleko jeszcze do uczynienia z tego systemu narzędzia praktycznego i przyjaznego użytkownikowi.
Spotkania
Materiały - Linki

