Opis
SemWeb_RDFize
Projekt
Introduction to the Semantic Web
The World Wide Web is the largest single information resource humanity has ever produced. Unfortunately, despite its dependence on computers to operate at all, most of the information is only understandable by humans and not by computers. While computers can use the syntax of HTML documents to display them to you in a browser, Web computers can't understand the content—the semantics.
The Semantic Web is Tim Berners-Lee's vision of the future of the Web. Although the dream is not yet realized, enough building blocks are now in place to enable you to take advantage of several Semantic Web technologies on your Web site, including RDF, OWL and SPARQL. The goal of the Semantic Web is to expose the vast information resource of the Web as data that computers can automatically interpret.
The Web was originally all about documents. The simple act of clicking on a link in your Web browser triggers your browser to ask a Web server to send you a document, which it then displays to you. The document might be your calendar for the next seven days, or it might be an e-mail from a friend. The Web browser doesn't really care; it just follows its internal rules for displaying the page. It's up to you to understand the information on the page.
Structuring data adds value to that data. With consistent structure, it can be used in more ways. You can see the demand for structured data today in the proliferation of APIs that have sprung up around Web sites as a part of the Web 2.0 trend—an API is structured data, and structured data from a variety of sources is what powers mashups. The idea behind mashups is that data is pulled from various sources on the Web and, when combined and displayed in a unified manner, this combination of elements adds value over and above the source information alone.
The individual APIs that everyone is busy building are to solve the exact same problem that the Semantic Web is intended to address: Expose the content of the Web as data and then combine disparate data sources in different ways to build new value. Rather than build and maintain your own API, you can build your Web site to take full advantage of the Semantic Web infrastructure which is already in place. If your Web site is your API, you can reduce the overall development and maintenance. Similarly, rather than build custom solutions for every Web site you want to pull data from, you can implement one solution based on Semantic Web technologies and have it work interchangeably across many Web sites—including Web sites you weren't even aware of before you began development.
Semantic Web technology overview
Semantic Web technologies can be considered in terms of layers, each layer resting on and extending the functionality of the layers beneath it. Although the Semantic Web is often talked about as if it were a separate entity, it is an extension and enhancement of the existing Web rather than a replacement of it.
The Semantic Web technology stack
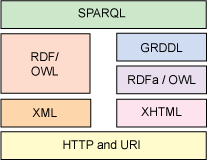
As shown in Figure 1, the base layer of the Semantic Web is HTTP and URIs. These are commonly considered 'Web' rather than 'Semantic Web', but every proposed Semantic Web technology rests upon these Web fundamentals. URIs are the nouns of the semantic Web. HTTP are the verbs: GET, PUT and POST as well as a number of thoroughly tested solutions in the fields of authentication and encryption.
The Resource Description Framework (RDF) is the workhorse of the Semantic Web. It is a grammar for encoding relationships. An RDF triple has three components: a subject, a predicate (or verb), and object. Each can be expressed as a resource on the Web, that is a URI. This is far less ambiguous than encoding data in random XML documents. Compare the different ways of expressing a simple relationship in XML with the RDF triple.
Ambiguous relationships in XML
<author>
<uri>page</uri>
<name>Rob</name>
</author>
<person name="Rob">
<work>page</work>
</person>
<document href="http://www.example.org/test/page" author="Rob" />
Expressing relationships in RDF (RDF Triple)
<page> <author> <Rob> .
The relationship expressed in all the examples in XML is 'Rob is the author of page'—a fairly simple statement—yet expressed in several ways in XML. It would be very difficult to build software that can derive that relationship from all the possible ways to express it in XML. But an RDF expresses that relationship in only one way, so it becomes feasible to build generic parsers.
In the early days of the Semantic Web, it was hoped that content producers would make all their content available in RDF and soon make a plethora of data available. Unfortunately, perhaps because the main XML expression of RDF looked unnecessarily complex, uptake was slow. More succinct RDF representations, like Notation3 (N3) and Terse RDF Triple Language (Turtle) are now available but have been unable to overcome the inertia. (For more on N3 and Turtle, see Resources.) A solution to the problem was inspired by the Microformats approach. With Microformats, semantic value is added to existing HTML content by using consistent patterns of standard HTML elements and attributes. Microformats exist for narrow but common items of data such as contact information and calendar items. The W3C equivalent is RDFa, RDF data embedded in XHTML. The implementation is slightly more complex than Microformats but it is far more generic—anything which you can express in RDF, you can add to XHTML documents using RDFa. Through this technique the Semantic Web can be bootstrapped by existing Web content.
Of course, the RDF embedded in XHTML documents as RDFa is no good for all the Semantic Web tools, which require RDF as input. There needs to be an automatic method to recognize the presence of RDFa content and extract the RDF out of it. The W3C solution for this is Gleaning Resource Descriptions from Dialects of Languages (GRDDL). The idea is that you run an existing XHTML document through an XSL transform to generate RDF. You can then link the GRDDL transform either through direct inclusion of references or indirectly through profile and namespace documents.
While unambiguously expressed semantics with RDF are good, even if everyone did that, it is of little use if you have no idea how the RDF from different sites is related. The RDF triple shown above expressed an author relationship in the predicate, and while the meaning might seem obvious to you, computers still need some help. If you expressed an author relationship in an RDF file on your site, could the computer assume they were the same thing? What if you instead had a writer relationship in your RDF triple? What you need is a way to express a common vocabulary, to be able to say that my author and your author are the same thing, or that 'author' and 'writer' are analogous. On the Semantic Web this problem is solved by ontologies, and the W3C standard for expressing ontologies is the Web Ontology Language (OWL).
Once you have some sources of data in RDF, and you have ontologies to let you determine the relationships between them, you need a way to get useful information out of them. The Simple Protocol and RDF Query Language (or SPARQL, pronounced 'sparkle') is an SQL-like syntax for expressing queries against RDF data, and the queries themselves look and act like RDF data. The fundamental paradigm for SPARQL is pattern matching and it is designed to work across the Web on data combined from disparate sources and to be flexible. For example, matches can be described as optional, which makes it much better than SQL at querying ragged data. Ragged data has an unpredictable and unreliable structure, which is what you might expect to find if your data is combined from various sources on the Web rather than from a single well-contained SQL database.
Semantic Annotation
Here is what we consider semantic annotations:
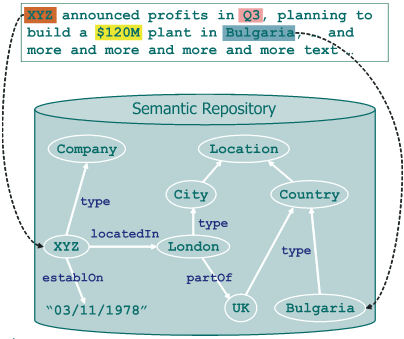
The information about what entities appear in a text and where they do. Actually, the references from the text to a semantic repository, containing further knowledge.
Annotation
'Annotation' has two meanings in contemporary English (according to WordNet, similar in Merriam-Webster):
note, annotation, notation: a comment (usually added to a text);
annotation, annotating – the act of adding notes.
In linguistics (and particularly in computational linguistics) an annotation is considered a formal note added to a specific part of the text. There are a number of alternatives regarding the organization, structuring, and preservation of annotations. For instance, all the markup languages (HTML, SGML, XML, etc.) can be considered as schemata for embedded annotation. Contrary there are models suggesting that the annotations should be kept detached (non-embedded) from the content, i.e.
Semantic Annotations
We refer to semantic annotation at the same time as (i) a sort of meta-data and (ii) the process of generation of such meta-data.
While there could be an argument with respect to the name (it could well be „Entity annotation”) its nature is quite unambiguous: the named entities in the text are recognized and identified. The result is formally recorded and associated with the place in the text where the entity has been mentioned. The identity of the entity is „verbalized” via URIs which means that those can be easily linked to their descriptions within a semantic repository, as demonstrated below.
Although redundant, in accordance with the good NE recongnition tradition in the IE community, the types of the entities are also explicitly indicated via URIs to the respective (most specific) classes in the ontology.
Named Entities
Named entities (NE) are considered: people, organizations, locations, and others referred by name. Apples and bicycles are not considered NE, because those are not typically referred by name.
Within a wider interpretation, NE can be considered also some scalar values (numbers, amounts of money, dates) and addresses.
Couple of principle comments:
Named entities and words have different semantics – the former denote particulars (individuals), the latter – universals (concepts, classes, relations, attributes).
While the words require handling of lexical semantics and common sense, the understanding and managing of named entities requires more specific world knowledge.
What about words?
Words can also be formally marked up. One of the typical approaches is to annotate the respective word with some sort of a designator of the word sense used in the specific case. For instance, a designator could be „link-v2”, meaning that the second meaning (according to some register) of the word „link” is taken as a verb (it could well serve as a noun).
There are number of tough issues relared to the word meanings:
Word Sense Disambiguation (WSD) - the process of guessing the meaning of the word used in this specific context. This is a very tough problem.
Formal definition of the meanings. While the first step is to distinguish and guess the sense, in which the word has been used, the next one is to define the meaning formally. There is no easy way to define „apple”, „know”, „synergy”, and even „house”, if you need a definition that helps one to answer „what is a house?”, „is this a house?”, etc.
RDFa
RDFa is a specification for attributes to express structured data in any markup language.
Marking up content with RDFa
The following block of HTML shows a review of a video game.
HTML:
<p><strong>Blast 'Em Up Review</strong></p>
<p>by Bob Smith</p>
<p>March 20, 2009</p>
<p>This is a great game. I enjoyed it from the
opening battle to the final showdown with
the evil aliens.</p>
<p>4.5 out of 5 stars</p>
Rendered HTML in browser:
Blast 'Em Up Review
by Bob Smith
March 20, 2009
This is a great game. I enjoyed it from the opening battle to the final showdown with the evil aliens.
4.5 out of 5 stars
To understand how to use RDFa, think about two concepts: entities (for example, a review) and properties of those entities (for example, the author of the review, the date of the review, the review itself, and the rating).
This is the HTML with RDFa markup:
<div xmlns:v="http://rdf.data-vocabulary.org/#" typeof="v:Review">
<p><strong><span property="v:itemReviewed">Blast 'Em Up</span>Review</strong></p>
<p>by <span property="v:reviewer">Bob Smith</span></p>
<p><span property="v:dtReviewed">March 20, 2009</span></p>
<p><span property="v:description">This is a great game. I enjoyed it from the opening battle to the final showdown with the evil aliens.</span></p>
<p><span property="v:rating">4.5</span> out of 5 stars</p>
</div>
This example contains three important properties:
xmlns. Occurs in the first line, and specifies the namespace where the vocabulary (a list of entities and their components) is specified. You can use the xmlns:v="http://rdf.data-vocabulary.org/# namespace declaration any time you are marking up pages for people, review, product, or place data. Be sure to use a trailing slash and # (xmlns:v="http://rdf.data-vocabulary.org/#" ).
typeof: Occurs in the first line of this
HTML block, and defines entities. Since this example contains a review, the entity is of type Review.
property: Used to label the properties of an entity. In the example, there are many properties of the review that are labeled: the reviewer, date of the review (dtReviewed), the review itself (description), and the rating (rating).
These three properties can be used in any HTML tags that open and close (div and span are two common choices). To mark up content using RDFa:
Begin with a namespace declaration using xmlns
Specify the type of content that is being marked up using typeof
Label the properties using property.
Relationships between entities in RDFa
In the example below, we describe two entities: a review and a person.
HTML:
<p><strong>Blast 'Em Up Review</p>
<p>by Bob Smith, Senior Editor at ACME Reviews</p>
<p>This is a great game. I enjoyed it from the opening battle to the final showdown with the evil aliens.</p>
<p>4.5 out of 5 stars</p>
Rendered HTML in browser:
Blast 'Em Up Review
by Bob Smith, Senior Editor at ACME Reviews
This is a great game. I enjoyed it from the opening battle to the final showdown with the evil aliens.
4.5 out of 5 stars
In this example, the relationship between the two entities is that the person is the reviewer who created the review. The review and person entities each have their own set of properties. The properties of the person are their name (Bob Smith), job title (Senior Editor), and company (ACME Reviews). The properties of the review are the reviewer (an entity), the review itself, and the rating (4.5).
To convey the relationship between the review and the person, we use the rel property. Here is how this example looks with RDFa markup:
<div xmlns:v="http://rdf.data-vocabulary.org/#" typeof="v:Review">
<p><strong><span property="v:itemReviewed">Blast 'Em Up</span>
Review</strong><p>
<p>by <span rel="v:reviewer">
<span typeof="v:Person">
<span property="v:name">Bob Smith</span>, <span property="v:title">Senior
Editor</span> at <span property="v:affiliation">ACME Reviews</span>
</span>
</span></p>
<p><span property="v:description">This is a great game. I enjoyed
it from the opening battle to the final showdown with the evil aliens.</span></p>
<p><span property="v:rating">4.5</span> out of 5 stars</span></p>
</div>
The following two lines define the relationship between the two entities:
<p>by <span rel="v:reviewer">
<span typeof="v:Person">
Here, by using rel instead of property, we define a relationship between the review and the person, namely that the writer of the review (the „reviewer”) is an entity (Person), with its own properties such as name, title, and org.
„rel” without „typeof”
The final concept to understand in order to mark up your content with RDFa is that rel can exist without an explicitly labeled typeof. In these cases, the entity is implicitly defined.
HTML Rendered HTML in browser
HTML:
<p><img src="www.example.com/bobsmith.jpg" /></p>
<p><strong>Bob Smith</strong></p>
<p>Senior editor at ACME Reviews</p>
<p>200 Main St</p>
<p>Desertville, AZ 12345</p>
Rendered HTML in browser:
Bob Smith
Senior editor at ACME Reviews
200 Main St
Desertville, AZ 12345
Here is the HTML with RDFa markup:
<div xmlns:v="http://rdf.data-vocabulary.org/#" typeof="v:Person">
<span rel="v:photo">
<img src="www.example.com/bobsmith.jpg" />
</span>
<p><span property="v:name"><strong>Bob Smith</strong></span></p>
<p><span property="v:title">Senior Editor</span> at <span property="v:affiliation">ACME Reviews</span></span></p>
<span rel="v:address">
<p><span property="v:street-address">200 Main St</span></p>
<p><span property="v:locality">Desertville</span></p>
<p><span property="v:region">AZ</span> </p>
<p><span property="v:postcode">12345</span></p>
</span>
</div>
In this example there are two implicitly defined entities: the person's photo and their address. Since the address property always relates to an entity of type address, there is no need to explicitly include a line with typeof=„v:Address”. Similarly, a photo always relates to a URL pointing to an image, so there is no need to explicitly define a typeof property.
Designed for humans first and machines second, microformats are a set of simple, open data formats built upon existing and widely adopted standards. Instead of throwing away what works today, microformats intend to solve simpler problems first by adapting to current behaviors and usage patterns (e.g. XHTML, blogging).
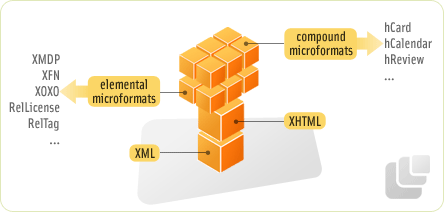
Microformats are:
A way of thinking about data
Design principles for formats
Adapted to current behaviors and usage patterns (“Pave the cow paths.”)
Highly correlated with semantic XHTML, AKA the real world semantics, AKA lowercase semantic web, AKA lossless XHTML
A set of simple open data format standards that many are actively developing and implementing for more/better structured blogging and web microcontent publishing in general.
Microformats are not:
A new language
Infinitely extensible and open-ended
An attempt to get everyone to change their behavior and rewrite their tools
A whole new approach that throws away what already works today
A panacea for all taxonomies, ontologies, and other such abstractions
Defining the whole world, or even just boiling the ocean
Any of the above
The microformats principles
Solve a specific problem
Start as simple as possible
Design for humans first, machines second
Reuse building blocks from widely adopted standards
Modularity / embeddability
Enable and encourage decentralized development, content, services
Embedded RDF
This document describes how a subset of RDF can be embedded into XHTML or HTML by using common idioms and attributes. No new elements or attributes have been invented and the usages of the HTML attributes are within normal bounds. This scheme is designed to work with CSS and other HTML support technologies.
Note: hereafter the term HTML will be used to include both XHTML and HTML except where otherwise stated.
Embeddable RDF
The subset of RDF that is used in this embedding scheme is called HTML Embeddable RDF. It allows some very important parts of the RDF model to be embedded but does not attempt to extend this to the full RDF model. This is very deliberate. Other attempts at embedding RDF in HTML have required the introduction of new syntax to express all the various RDF concepts.
The relationship is: all HTML Embeddable RDF is valid RDF, not all RDF is Embeddable RDF.
Existing ontologies
A more complex part of the Semantic Web is to design an ontology that matches up to your data. Arriving at the right ontology is usually a critical element of successful implementation of Semantic Web projects. Fortunately, many ontologies already exist.
Some ontologies in use on the Web today
| Dublin Core | This metadata element standard for cross-domain information resource description provides a simple and standardised set of conventions for describing things online in ways that make them easier to find. |
| SIOC | Semantically-Interlinked Online Communities Project is an ontology that expresses the information contained both explicitly and implicitly in Internet discussion methods, such as blogs or forums mailing lists. |
| FOAF | The Friend of a Friend ontology describes individuals, their activities and their relations to other people and objects. FOAF allows the description of social networks in a distributed fashion. |
| DOAP | Description Of A Project is an ontology to describe open-source projects |
| ResumeRDF | This ontology expresses a Resume or Curriculum Vitae (CV), including information such as work and academic experience or skills. |
In addition, many ontologies are domain specific in fields such as technology, environmental science, chemistry and linguistics. These will apply to fewer Web sites than those listed above, however. A lot of your data is likely to fit into at least one of the areas covered by the listed ontologies, in which case you can incorporate them in your planning.
Whether you fully embrace the Semantic Web in your Web site infrastructure, or just want to make your existing content more useful, there are probably several opportunities to add structure to existing content on your Web site. This is the domain of Microformats, RDFa and GRDDL. Below are listed more common information types that you can easily mark up as structured data.
Opportunities for structured markup and automatic transformation
| Information type | Structured Markup |
| People and Organizations | hCard, RDF vCard |
| Calendars and Events | hCalendar, RDF Calendar |
| Opinions, Ratings and Reviews | VoteLinks, hReview |
| Social Networks | XFN, FOAF |
| Licenses | rel-license |
| Tags, Keywords, Categories | rel-tag |
| Lists and Outlines | XOXO |
Adding the structured markup to your page is fairly simple. Below is shown a fragment of HTML containing contact information without, and then with, the additional markup required for the RDF vCard, respectively.
Unstructured contact information
<div class="contactinfo">
Rob Crowther. Web hacker
at
<a href="http://example.org">
Example.org
</a>.
You can contact me
<a href="mailto:robertc@example.org">
via e-mail
</a> or on my work phone at 0123 456789.
</div>
Below you can see the contact information with additional markup required for the RDF vCard.
Contact Information using vCard
<div xmlns:contact="http://www.w3.org/2001/vcard-rdf/3.0#" class="contactinfo" about="http://example.org/staff/robertc">
<span property="contact:fn">Rob Crowther</span>.
<span property="contact:title">Web hacker</span>
at
<a rel="contact:org" href="http://example.org">
Example.org
</a>.
You can contact me
<a rel="contact:email" href="mailto:robertc@example.org">
via e-mail
</a>
or on my
<span property="contact:tel">
<span property="contact:type">work</span>
phone at
<span property="contact:value">0123 456789</span>
</span>.
</div>
As you can see span elements added to delimit the semantically significant bits of text, and attributes that indicate what they mean. You added the namespace „contact” linked to the RDF VCard vocabulary. Next, you indicated that this element is about the resource represented by the URI http://example.org/staff/robertc. Then, you added metadata using the rel attribute for link relationships and the property attribute on non-links. The only slightly complex part is the telephone because you need to specify a type as well as the number. To achieve this, you nest the type and value elements inside the tel element. Adding this structure allows users to add the contact details to their address book with a single click of the mouse.
Other automatic processing is possible with the other structured forms; for example, Technorati makes use of the rel-tag microformat to categorize its vast aggregation of blog posts. A rel-tag is shown below, and as you can see, it is simply a link that makes use of the rel attribute. The significant part is the last bit of the URI, after the final /. This is the tag (using the normal URI encoding conventions where a space is represented by the plus sign).
rel-tag for Technorati for the tag 'semantic web'
<a href="http://technorati.com/tag/semantic+web" rel="tag">
Semantic Web
</a>
Browser Plugins
Fuzz is most useful for detecting embedded semantic information in web pages. It is currently the most compliant in-browser RDFa parser.
JavaScript Bookmarklets to drag to your
IE, Firefox, Safari toolbar to extract, display and interact w/ RDFa. Great for demonstration purposes and for quickly checking RDFa you've added to your page.
MozCC is an extension for Mozilla-based applications, including Mozilla Firefox and Songbird, which provides a convenient way to examine metadata – including Creative Commons licenses – embedded in web pages.
Operator, a Firefox plugin and an extension.
Semantic Radar for Firefox, a semantic metadata detector for Mozilla Firefox.
Web-based Services
FOAFr enables the conversion of your RDF FOAF file into RDFa.
irs allows to create typed links between resources and export as XHTML+RDFa (note: early alpha).
mle creates SIOC in XHTML+RDFa from hypermail archives.
RDFohloh exports the information stored in Ohloh in RDF/XML, N3 and XHTML+RDFa.
Sindice is a semantic web crawler that parses and indexes RDFa.
SPARQLBot, an
IRC bot consuming RDFa; allows you to perform user-defined SPARQL queries on data sources from
IRC. See the SPARQLBot documentation for how to use it.
Yahoo Search Monkey crawls the web looking for RDFa data that use particular vocabularies.
Swignition a parser for metadata embedded in
HTML, extracts a number of other microformats as well
Applications
Swignition a parser for metadata embedded in
HTML, extracts a number of other microformats as well
Exhibit can import data on the fly from RDFa in pages within the same domain.
Krextor is a generic XML→RDF extraction library (with a command-line frontend) with support for XHTML+RDFa input (currently in an experimental stage) and support for RDFa integrated into other host languages.
OpenLink Data Spaces, a distributed collaborative applications suite for creating and exploiting presence on the Linked Data Web that includes support for RDFa consumption and generation (all ODS Web pages can optionally include RDFa generated by the system as an addition mechanism for exposing RDF in a given data space).
TopBraid Composer is an enterprise-class modeling environment for developing Semantic Web ontologies and building semantic applications. It supports RDFa.
Virtuoso, a SPARQL compliant Quad Store that includes an RDFization layer (within its SPARQL processor) with support for RDFa.
In-browser RDFa Tools
Content Management Plugins
HTML+RDFa Editors
Exporting Content as RDFa
RDF Generators
Cypher - Cypher Generates RDF and SPARQL/SeRQL representation of natural language statements and phrases
FOAF-o-matic - FOAF-o-matic Online FOAF generator
INQLE -
http://code.google.com/p/inqle/ Intelligent network of Querying and Learning Engines. Open Source server, with Jena SDB back-end datastore. Runs automated, random machine learning experiments on semantic data. Stores any discovered correlations as RDF, and leverages such correlations in performing future experiments. Provides tools for loading spreadsheet data into the RDF database.
Krextor - Krextor is a framework for extracting RDF from various XML languages (see this wiki page for details)
Ontos - Ontos
API is a public web service which returns rich semantic metadata in standard RDF-based formats for input plain text content you submit. Ontos recognizes entities and relations between them using natural language processing techniques. Although basic types of entities (people, companies, places etc.) are pre-defined, the user can also create OWL-driven dictionaries for custom types of entities, merge entities across documents, etc. For more details, tips and updates see Ontos
API home, the official blog, and the community group.
Open Calais - Open Calais from [Reuters
http://www.reuters.com] is a web service that automatically attaches rich semantic metadata to the content you submit. Using natural language processing, machine learning and other methods, Calais categorizes and links your document with entities (people, places, organizations, etc.), facts (person ‘x’ works for company ‘y’), and events (person ‘z’ was appointed chairman of company ‘y’ on date ‘x’). The metadata results are stored centrally and returned as RDF constructs.
OpenLink Virtuoso - OpenLink Virtuoso (elsewhere on this page) delivers SQL2RDF directly, and via the Sponger and its cartridges, also delivers RDF from GRDDL, RDFa, microformats, and many more inputs.
RDFa distiller - downloadable Python package as well as online service to generate RDF from RDFa pages
Semantic Hacker - Semantic Hacker's technology provide a weighted representation of the concepts contained in a piece of text. (It does not provide RDF directly yet…)
Triplify - Triplify is a small plugin for Web applications, which reveals the semantic structures encoded in relational databases by making database content available as RDF, JSON or Linked Data.
Zemanta - Zemanta
API is a web
API that delivers relevant tags, links, categories and pictures from your unstructured data/content. It is semantic standards compliant, with RDF output and ability to disambiguate to entities from Linking Open Data.
Sample applications/websites
Wandora
Wandora is a general purpose knowledge extraction, management, and publishing application based on Topic Maps and Java. More precisely Wandora is an open source desktop application to build and manage topic maps. Wandora has graphical user interface, layered presentation of knowledge, several data storage options, rich data extraction, import and export capabilities, and open plug-in architecture. Wandora's license is GNU GPL.

Wandora suits well for knowledge mashups. Wandora is capable to extract and convert various open data feeds to Topic Maps format (see image below). Beyond Topic Maps conversion this feature allows Wandora user to aggregate multidimensional knowledge bases where information from Flickr meets Geonames and Delicious, for example. Read more at documentation.
This site, WandoraWiki, is a home of Wandora software application and provides you an access point to the Wandora application and it's documentation. To contribute Topic Maps, Wandora Team has also converted several well known ontologies to Topic Maps format. These converted ontologies; WordNet, OpenCyc, Gene Ontology, Gellish, and Finnish General Upper Ontology (YSO) are available for download here in WandoraWiki.
SemanticProxy
SemanticProxy.com is part of the Calais Initiative from Thomson Reuters.
In the future the entire web will be one giant tightly interconnected information asset. Beyond just publishing information for humans, every site will expose its content in a way that's readable by machines. Those machines will mix, match, filter and aggregate information to greatly improve things for us humans. We're not there yet - but that's the vision of the Semantic Web.
SemanticProxy.com is a little taste of what that future might look like. What SemanticProxy does is simple: it translates the content of any URL on the web to its semantic representation in RDF, HTML or Microformats. If you're an RDF crawler hungry for a little semantic content, just point yourself at SemanticProxy.com and we'll fill you up.
Right now SemanticProxy.com is optimized for performance on 30 of the world's largest English-language news sites. In coming releases we'll continue to refine and extend its capabilities to additional areas. While you'll find it works best with news, feel free to experiment with other sites like Wikipedia or … whatever. The results can be very encouraging.
SemanticProxy isn't intended to be a great place for humans to visit. However, little semantic machines love to come by and spend a few high-quality milliseconds.
Gnosis
Delivering Semantic Web Services - Directly to Your Desktop
Gnosis is a browser extension for Firefox and Internet Explorer that automatically analyzes content as you browse and provides a variety of tools to explore the people, places, companies, and other items that you’re reading about. In this latest release, Gnosis capability has been extended to include the following:
Support for Firefox 3.5
Entity Count and Relevance Score for each entity that the viewer displays.
Entity Disambiguation: The entity name displayed is the disambiguated name where applicable (companies, geographies, electronic products)
After installing Gnosis, simply navigate to the news site that you are interested in - one of the news sites listed below would be a good place to start. Right-click and select ClearForest Gnosis or click on the Gnosis button in the toolbar. After 1-2 seconds your page has been processed and you’re ready to explore!
RDFa Implementations
There are a number of RDFa implementations.
Python
Author: Ivan Herman
http://www.w3.org/2007/08/pyRdfa/
Author: Nathan Yergler
http://pypi.python.org/pypi/rdfadict
Author: Elias Torres
http://svn.rdflib.net/trunk/rdflib/syntax/parsers/RDFaParser.py
PHP
Author: Benjamin Nowack (semsol)
http://arc.semsol.org/download
* RDFa Monkey
Author: Ruben Thys
http://www.avthasselt.sohosted.com/rdfamonkey/
XSLT
Author: Fabien Gandonhttp:ns.inria.fr/grddl/rdfa/
JavaScript
* RDFa Bookmarklets
Author: Ben Adida
http://www.w3.org/2006/07/SWD/RDFa/impl/js/
Ruby
* RDFa on Rails
Author: Cédric Mesnage
http://rdfa.rubyforge.org/
* ruby-rdfa
Author: Benjamin Lyu
http://code.google.com/p/ruby-rdfa/
C/C#
* librdfa
Author: Manu Spornyhttp:rdfa.digitalbazaar.com/librdfa/



