Opis
Projekt zakończony
Lukasz Zalewski, zalewik@gmail.com
High-level NXT programming, design tools, XTT applications
Spotkania
Projekt
Regułowe algorytmy sterowania
 Poniższe algorytmy zostały opracowane dla robota mobilnego TriBot. Jest to rozbudowana wersja robota z katalogu zestawu mindstorm:
W algorytmach wykorzystano wszystkie użyte sensory (tak jak widać na obrazku: echosonda, mikrofon, czujnik dotyku i sensor natężenia światła).
Poniższe algorytmy zostały opracowane dla robota mobilnego TriBot. Jest to rozbudowana wersja robota z katalogu zestawu mindstorm:
W algorytmach wykorzystano wszystkie użyte sensory (tak jak widać na obrazku: echosonda, mikrofon, czujnik dotyku i sensor natężenia światła).
-
-
-
-
-
Wadą powyższych algorytmów jest brak informacji o położeniu. Robot nie ma punktów odniesienia. Nie zna swojej pozycji. Stąd trudno wymagać, by poruszał się w zadanym kierunku nawet po napotkaniu przeszkody. Sytuację tą można poprawić wprowadzając możliwość zapisu pomiarów z czujników.
Algorytmy genetyczne
Można również rozważyć wykorzystanie algorytmów genetycznych do sterowania robotami. Tym zagadnieniem zajmują się już inne uczelnie Southwestern University, Georgetown, TX
Bardzo ciekawe zastosowanie algorytmów genetycznych w przypadku robotów zaprezentowano na naukowym zjeździe fundacji Ted. Przedstawiono tam algorytm, który sam generuje sterowanie wiedząc tylko tyle, że ma kilka serwomechanizmów i czujników.
Pliki Hqed
Sprawozdanie
Opisane algorytmy sterowania z internetu
W pierwszej iteracji projektu należało znaleźć możliwie jak najwięcej przykładów sterowania robotami. Niestety, informacji na ten temat jest niewiele. Większość materiału jest nie udokumentowana, cześciej spotykane były wzmianki lub prezentacje sterowania robotami.
Ciekawostką jest to, że również inne europejskie uczelnie zajmują się opracowywaniem sterowania, prowadzą laboratoria z MindStormów.
Udokumentowane algorytmy (przykłady) sterowania robotami mobilnymi - z sieci:
Algorytmy - zapis regułowy
W drugiej iteracji należało zastanowić się i zapisać algorytmy sterowania dla wymyślonego robota Mindstorm. Do tego celu użyto robot TriBot, który zawiera wszystkie dosŧępne sensory.
Przy zapisie regułowym pojawiło się parę niejasności:
Czy reguły mają się wykluczać? I jeżeli nie, to wówczas jaki przyjąć sposób ich „odpalania”.
Czy mogą zostać użyte więcej niż jedna reguła na raz?
Od tych zasadniczych pytań zależy sposób zapisania reguł. Wydaje się oczywiste, że najlepiej byłoby dążyć do tego by reguły były zupełne i jednocześnie wykluczały się. Jednak taki zapis nie jest prosty. Oraz narzuca pewne wymogi.
W projekcie wykorzystano zarówno reguły wykluczające się jak i takie, które są luźne. Przy tych ostatnich przyjęto, że wywoływana jest pierwsza poprawna reguła (zapis ten przypomina Prolog).
| | Reguły wykluczające się | Luźny zapis |
| | + pewniejszy zapis | + brak ograniczeń |
| | + proste zasady | + mniej reguł |
| | - większa ilość reguł | - problem z wywolywaniem reguł |
| | - narzucona koncepcja. W niektórych przypadkach utrudnia zapis | |
| Pojedyncze wywołanie | Jest to najlepsze sposób wywoływania | Prowadzi do formalizacji(szczegułowaści) zapisu, zwiększa ilość reguł |
| Monitorowanie | Nie jest potrzebne | Może prowadzić do wywołania więcej niż jednej reguły |
| Nawroty | Są zbędne, niczego nowego nie wprowadzają | Najlepsze podejście. Reguły tworzą logiczną ścieżkę przejść |
Po przyjęciu sposobu zapisu reguł i przyjęciu mechanizmu ich wywoływania, przystąpiono do ich zapisu. I tu również pojawił się problem. Mianowicie, w przypadku bardziej złożonych algorytmów trudno było wydzielić takie elementy jak:
Czy raz wpisana wartość atrybutu zostaje zachowana do następnej zmiany?
| Atrybuty z pamięcią | Atrybuty bez pamięci |
| + dodatkowa informacja o stanie robota | + brak konieczności zapewniania zerowaniana wartości |
| - należy pamiętać, że wówczas inkrementujemy wartości, np. turn += 45 zamiast turn = 45 | + prosty zapis |
| - konieczność zerowania wartości w celu np. zatrzymania robota po wykonaniu reguły | - zerowanie wymusza konieczność ponownego pozyskania informacji o stanie robota co prowadzi do zwiększenia ilości atrybutów |
| | ? zerowanie powinno odbywać się albo po wykonaniu reguły, albo przy kolejnym cyklu (metoda „Pojedyncze wywołanie”) |
W projekcie przyjęto, że dla zapisu regułowego algorytmów atrybuty są wartościami bez pamięci.
Podjęto próbę dokonania zapisu wg przykładu z termostatem. Czyli dokonania grupowania atrybutów. Głównym napotkanym problemem było oddzielenie akcji od atrybutów. Częst zdażało się, że atrybut był akcją. Upakowywanie atrybutów i akcji często prowadziło do zwiększenia ilości reguł oraz do mniejszej czytelności. W miarę możliwości powinno się upraszczać opis do reguła→akcja
| Atrybuty - prosty zapis | Atrybuty - zapis złożony (upakowywanie atrybutów, np. termostat) |
| + prostota | + bardziej przejrzysta forma zapisu |
| - więcej warunków wstępnych do wykonania reguły | + logiczna konsekwencja zapisu reguł |
| - przy dużej ilości warunków reguły tracą czytelność | - zazwyczaj prowadzi do zwiększenia ilości reguł |
Prolog - UWAGI
W trzeciej części iteracji projektu należało zapisać wcześniej wymyślone algorytmy przy użyciu funkcji nxt_movements w Prolog'u. Cel był prosty. Sprawdzono użyteczność stworzonych predukatów. Część z nich była nadmiarowa. Jednak stworozne API przez pana Hołownię w zupełności wystarczyło do zapisania algorytmów sterowania. Wszelkie uwagi oraz spostrzeżenia były konsultowane z kolegą. Uwag było niewiele. Zatem przygotowane funkcje były jak najbardziej poprawne z punktu widzenia użytkownika.
Podczas tworzenia algorytmów w Prolog'u przy alokacji dodatkowych zmiennych korzystano z funkcji assert. Tu możana by się zastanowić nad wprowadzeniem predykatów alokacji pamięci dla Mindstorma, jeżeli jest to konieczne.
W sterowaniu robotem najtrudniejszym elementem było zapamiętanie stanu robota. Należało tworzyć dodatkowe zmienne, tablice przechowyjące stan robota. Jako, że korzystanie ze stanów poprzednich jest tu w zasadzie elementarną operacją, można zastanowić się również na wprowadzeniu historii ruchów w postaci jakiś logów, do których możnaby odwoływać się odpowiednimi predykatami. Takie zapisane stany mogłyby ułatwić, ujednolicić oraz sformalizować zapis algorytmów.
XTT - UWAGI
W czwartej iteracji należało zapisać reguły przy użyciu XTT. Ponieważ, XTT jest tylko formą zapisu zwykłych reguł, więc zapisane reguły na ogół nie różniły się od tych z 2 iteracji. W niektórych przypadkach odstąpiono od tej zasady i probowano zapisać reguły zmieniając atrubuty.
Tak jak poprzednio w iteracji 2 pojawiają się problemy:
podział na atrybuty i akcje
czy atrybuty/akcje są zerowane, czy też mają pamięć?
jak uruchamiać XTT?
pojedyncze wywołanie?
monitorowanie?
nawroty?
brak znacznika START'u/STOP'u
problem operowania na większej ilości danych, np. tablice
puste przebiegi jako defaultowa reguła (konstrukcja else), czy mogą być używane?
wielokrotne zapętlanie algorytmu prowadzi do nieczytelności
Te i wiele innych problemów zauważono przy korzystaniu z XTT. Ponieważ, zapis XTT, w moim odczuciu powinien być jak najbardziej elastyczny, postanowiłem odejść od formalnego zapisu jak np. termostat i postanowiłem zapisywać algorytmy na różne sposoby.
UWAGI!!!
Tworzenie algorytmu od postaw:
Dodawanie atrybutów
Znacznik rozpoczęcia programu. W przypadku wielu tablic warunkowych na początku XTT powinien być jakiś znacznik wskazujący START programu. Może być systuacja taka, że za tablicami 'fact table' pojawiają się tablice z warunkami bardzo podobnymi i wówczas należy wskazać, która tablica jest nadrzędna. Oczywiście projektant powinien unikać takich sytuacji, ale mimo wszystko może zaistnieć taka sytuacja.
Puste przebiegi. Może pojawić się potrzeba wprowadzenia pustych reguł, które spełniały by rodzaj konstrukcji
else.
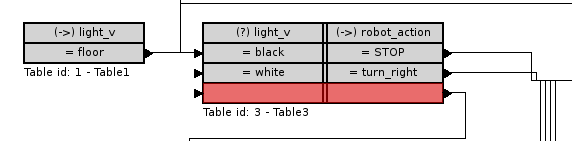
Zapętlanie reguł. Bardzo przydatne okazuje się w niektóruch przypadkach wprowadzanie pętli. Można stworzyć w ten sposób dowolną pętlę.

-
Sposób wywoływania reguł w zasadzie niewiele koncepcji można tu wymyśleć. Czy zostanie przyjęty system wywołania pojedynczego co jakiś okres, czy zastosowane zostaną nawroty (w sensie zapętlania programu) to zasada i tak zostanie ta sama. Jedynym aspektem, nad którym można by się zastanawiać to moment aktualizowania danych wejściowych z 'fact table'. Bo to czy aktualizacja nastąpi podczas jednego przebiegu (gdzie przebiegiem nazywamy przejście od tablicy początku do końca), czy w trakcie, bądź też np. podczas spływania sygnałów do tablicy, nabiera znaczenia.
Wydaje mi się, że niezależnie od sposobu przedstawiania atrubutów (np. termostat lub zwykły zapis prostych atrybutów), to zapis XTT powinien:
przybierać postać alternatywnych ścieżek przejścia reguł
powinna być możliwość wprowadzanie zapętlania reguł
powinna być możliwość stosowania pustych reguł, gdyż ułatwiają one zapis
XTT powinien być na tyle elastyczny, by mogła zostać zapisana dowolna struktura na potrzeby bardziej złożonych algorytmów.
ARD - UWAGI
W piątej iteracji należało zastanowić się nad ujęciem algorytmów w ARD.
wydzielanie atrybutów dla algorytmów sterowania nie zawsze jest łatwe. Pojawiają się problemy z rozróżnieniem akcji od atrybutu.
również, atrybuty występują w w różnych częściach algortymu. Stąd, relacje pomiędzy atrybutami często są złożone. Przejawia się to choćby w późniejszej realizacji XTT. Czytelność XTT jest słaba.
Program HQED - UWAGI
Wszystkie poniższe bugi zostały już zgłoszone przez kolegę Łukasza Rachwalskiego.
podczas przeciągania połączenia od jednej tabeli do drugiej pojawiają się błędy. A dokładniej linia (connector) nie podąża za kursorem, co uniemożliwią dokonanie poprawnego połączenia tabel
obecna wersja programu nie jest jeszcze stabilna. Program zawiesza się np. przy wprowadzaniu danych do tabel.
Materiały
Oprócz wyżej zaprezentowanych materiałów znaleziono:
google.books.com zawiera wiele materiałów z gotowymi projektami LEGO MINDSTORMS. W tym jak zbudować i zaprogramować roboty jeżdżące, chodzące itp.
na sieci znajduje się wiele rozważań dotyczących tematyki sterowania robotami mobilnymi. Są to jednak prace ujmujące zagadnienie w sposób matematyczny. Tworzone są modele matematyczne, a następnie analizowane są przeprowadzone wcześniej symulacje. Np:
zfilmowane projekty robotów:



