Spis treści
Drzewa decyzyjne
Drzewo decyzyjne to graficzna metoda wspomagania procesu decyzyjnego, stosowana w teorii decyzji. Algorytm drzew decyzyjnych jest również stosowany w uczeniu maszynowym do pozyskiwania wiedzy na podstawie przykładów.
Przykład drzewa decyzyjnego
Przykładowe drzewo decyzyjne (dla danych z weather.nominal.arff.zip) zostało przedstawione poniżej.

Pytanie: Jak Twoim zdaniem wyglądałoby drzewo decyzyjne dla zestawu danych poniżej, spróbuj narysować je na kartce.
| Sky | AirTemp | Humidity | Wind | Water | Forecast | Enjoy |
|---|---|---|---|---|---|---|
| sunny | warm | normal | strong | warm | same | yes |
| sunny | warm | high | strong | warm | same | yes |
| rainy | cold | high | strong | warm | change | no |
| sunny | warm | high | strong | cool | change | yes |
| cloudy | warm | normal | weak | warm | same | yes |
| cloudy | cold | high | weak | cool | same | no |
Algorytm ID3
Algorytm ID3 służy do budowania drzew decyzyjnych. Bazuje on na dwóch parametrach, które wyliczane są dla każdego nowego węzła drzewa decyzyjnego. Parametry te to:
- Entropia - będąca miarą zróżnicowania danych
- Przyrost wiedzy (Information Gain) - miara różnicy Entropii przed i po rozbiciu zbioru danych
 przy pomocy atrybutu
przy pomocy atrybutu 
Entropia

Gdzie
- - Aktualny zbiór danych dla którego liczona jest entropia (dla każdego węzła drzewa będzie to inny - odpowiednio mniejszy zbiór danych)
 - zbiór klas w zbiorze
- zbiór klas w zbiorze  - Stosunek liczby elementów z klasy
- Stosunek liczby elementów z klasy  do liczby elementów w zbiorze
do liczby elementów w zbiorze
Przyrost wiedzy (Information Gain)

Gdzie,
 - Entropia dla zbioru
- Entropia dla zbioru  - zbiór wszystkich wartości atrybutu
- zbiór wszystkich wartości atrybutu  - Podzbiór S, taki że:
- Podzbiór S, taki że: 
 - Entropia podzbioru
- Entropia podzbioru
Algorytm ID3 w pseudokodzie
ID3 (Examples, Target_Attribute, Attributes)
Create a root node for the tree
If all examples are positive, Return the single-node tree Root, with label = +.
If all examples are negative, Return the single-node tree Root, with label = -.
If number of predicting attributes is empty, then Return the single node tree Root,
with label = most common value of the target attribute in the examples.
Otherwise Begin
A ← The Attribute that best classifies examples (highest Information Gain).
Decision Tree attribute for Root = A.
For each possible value, v_i, of A,
Add a new tree branch below Root, corresponding to the test A = v_i.
Let Examples(v_i) be the subset of examples that have the value v_i for A
If Examples(v_i) is empty
Then below this new branch add a leaf node with label = most common target value in the examples
Else below this new branch add the subtree ID3 (Examples(v_i), Target_Attribute, Attributes – {A})
End
Return Root
Pytanie Korzystając ze zbioru danych z tabeli z poprzedniej sekcji, policz entropię i przyrost wiedzy dla poszczególnych atrybutów. Uwaga - w przykładzie mamy do czynienia z problemem binarnym, więc sumy ze wzorów tak naprawdę będą tylko dwuelementowe (poza liczeniem information gain dla atrubutu sky).
- Dla którego z atrybutów entropia jest największa?
- Dla którego z atrybutów information gain jest największy?
- Analizując wyniki, czy dobrze wybrałeś(aś) korzeń drzewa w pytaniu z poprzedniej sekcji?
Wprowadzenie do Weki
Weka, to narzędzie opensource do data miningu. Uruchom je wykonując w konsoli polecenie. Jeśli program nie jest zainstalowany, ściagnij go ze strony
$ weka
Jeśli program nie jest zainstalowany, ściągnij go ze strony: Weka i uruchom:
$ java -jar weka.jar
Wczytywanie i analiza danych
- Pobierz paczkę plików z danymi: data.tar.gz
- Otwórz w Gedicie plik o nazwie swimming.arff i poznaj strukturę plików uczących dla weki z danymi symbolicznymi.
- Uruchom Wekę i kliknij w przycisk Explorer
- Przeanalizuj pierwszą zakładkę GUI i odpowiedz na pytania poniżej:
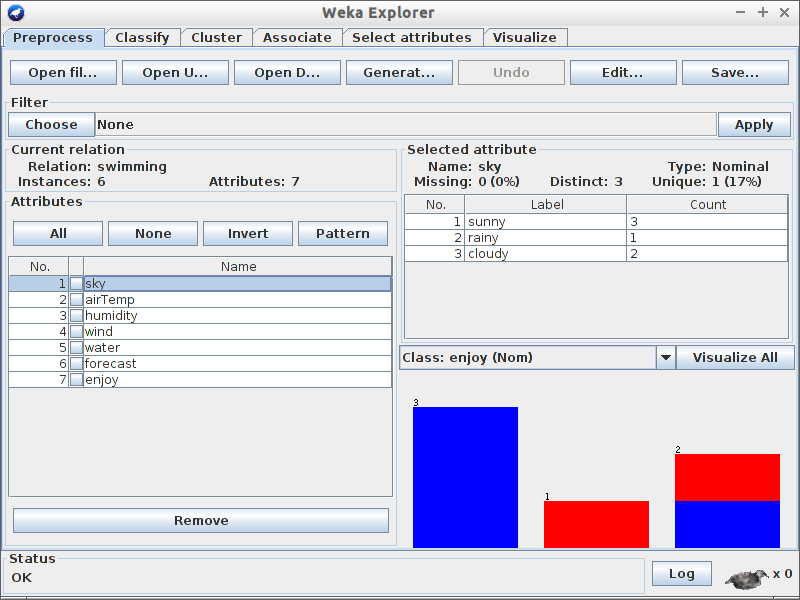

Pytania
- Jaki jest rozmiar zbioru uczącego?
- Ile atrybutów występuje w zbiorze uczącym?
- Ile jest instancji jest pozytywnych (Enjoy=yes) a ile negatywnych?
- Który z atrybutów najlepiej rozdziela dane? ;)
- Ile elementów ze zbioru danych ma atrybut wilgotność (humidity) ustawioną jako high?
Drzewa decyzyjne
- Wczytaj plik swimming.arff ze zbioru danych
- Kliknij w zakładkę Clasify
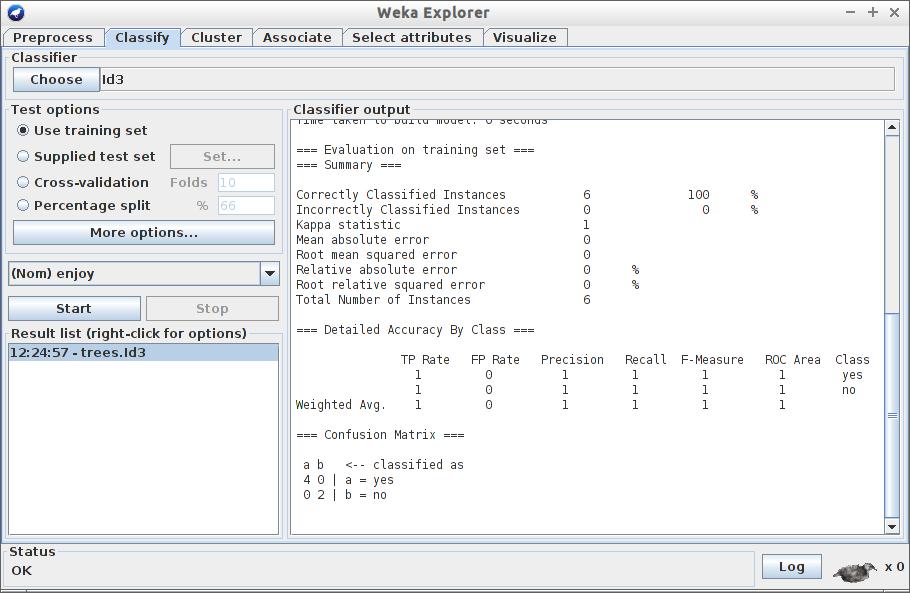
- Wybierz za pomocą przycisku Choose klasyfikator Id3.
- Upewnij się, że w oknie Test options zaznaczona jest opcja Use training set. Uwaga! W przyszłości nie będziemy korzystać z tej formy testowania - tutaj jesteśmy zmuszeni, z uwagi na niewielki zbiór uczący.
- Kliknij w przycisk Start. Przyjrzyj się rezultatowi. Co oznaczają wyniki?
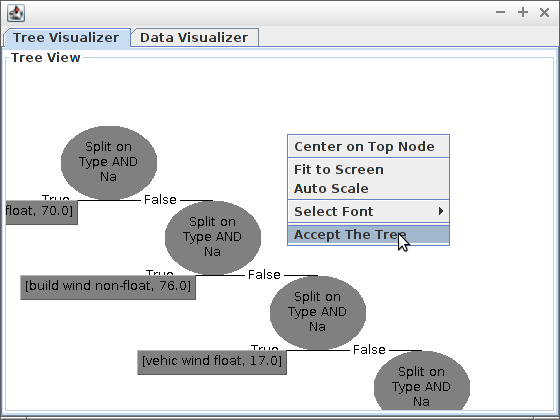
- Wybierz za pomocą przycisku Choose klasyfikator J48 i kliknij Start, następnie zwizualizuj drzewo tak jak to pokazano poniżej:
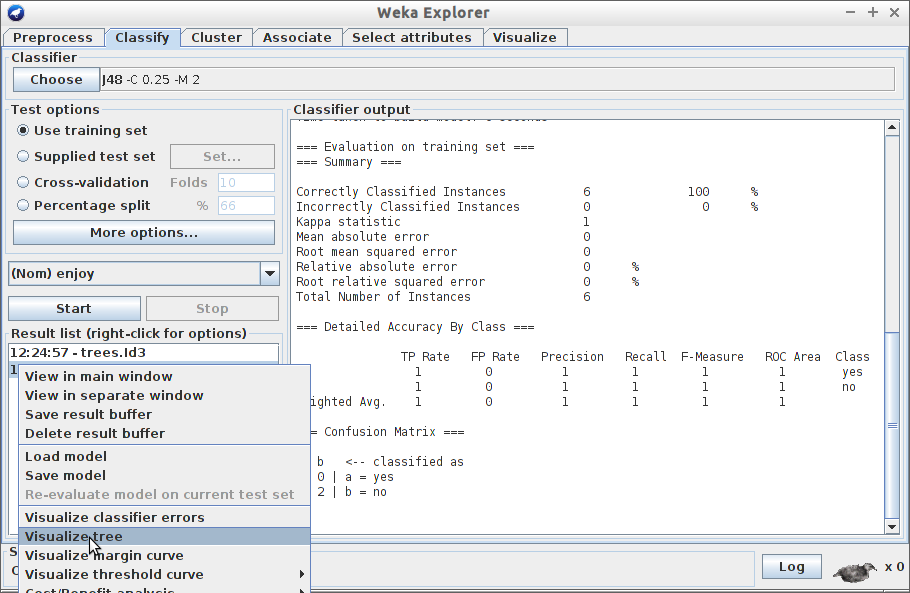
- Czy drzewo wygląda tak jak je narysowałeś(aś) na początku laboratorium?
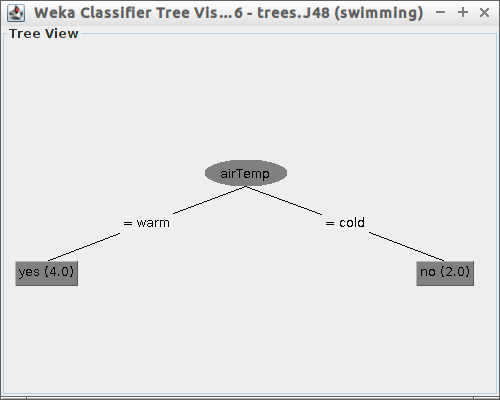



Poprawność klasyfikacji
- Załaduj plik credit-g.arff do Weki. Zawiera on dane uczące dla systemu, który na podstawie atrybutów zawartych w pliku powinien określać czy dany zestaw wartości atrybutów wskazuje na wiarygodnego klienta banku, czy też nie - czy można przyznać mu kredyt, czy jest to ryzykowne.
- Przejdź do zakładki Classify i wybierz algorytm J48.
- W obszarze Test options wybierz opcje Percentage split z wartością 66% Oznacza to, ze 66% danych posłuży do uczenia, a 34% do walidacji. Jakie to ma znaczenie?
- Uruchom algorytm. Ile procent przypadków zostało poprawnie zaklasyfikowanych? Czy to dobry wynik?
- Zmień klasyfikator na ZeroR z gałęzi rules. Jakie są wyniki?
- Wypróbuj inne klasyfikatory. Jakie dają wyniki?
- Przejdź do zakładki Preprocess i zobacz jak wygląda rozkład atrybutu określającego czy danych zestaw jest dobry czy zły. Jaka byłaby skuteczność algorytmu który niezależnie od wartości atrybutów „strzelałby” że użytkownik jest wiarygodny?
- Dlaczego przed przystąpieniem do klasyfikacji, warto wcześniej przyjrzeć się danym? ;P
User Classifier
- Zbuduj drzewo z wykorzystaniem klasyfikatora „User Classifier” dla danych z pliku (użyj PPM do „domknięcia” wielokąta):
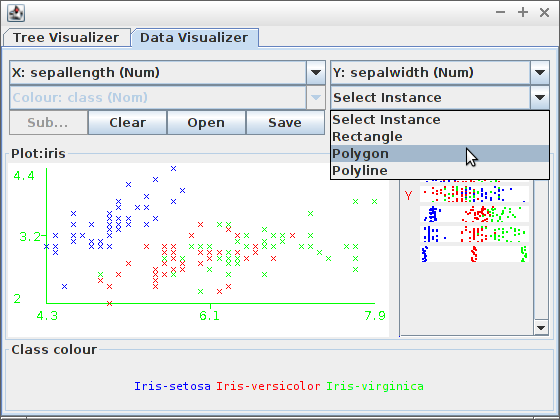
- Zaakceptuj zbudowane drzewo i zobacz wyniki: