Spis treści
LAB: Uczenie nienadzorowane
Laboratorium kontynuuje poprzednie zajęcia rozszerzając wiedzę dotyczącą sposobów nabywania wiedzy przez inteligentnych agentów o wybrane metody uczenia nienadzorowanego.
Laboratorium zostało przygotowane w oparciu o materiały z kursów: Data Mining with Weka, More Data Mining with Weka i Machine Learning oraz w oparciu o materiały udostępniane z podręcznikiem Artificial Intelligence: Foundations of Computational Agents.
1 Do przygotowania
- [ArtInt] Section 10.2 Unsupervised Learning (i podsekcje)
- [AIMA] Section 20.3.1: Unsupervised clustering: Learning mixtures of Gaussians (a.k.a. EM)
- Reguły asocjacyjne i algorytm Apriori: slajdy 1-19 z pdfa
2 Reguły asocjacyjne
Reguły asocjacyjne przypominają reguły decyzyjne omawiane na jednym z poprzednich laboratoriów. Tym razem jednak decyzja (prawa strona implikacji) nie jest z góry określona, tzn. nie wiemy, na którym atrybucie ma się opierać. Jest to przykład nauki bez nauczyciela: algorytm nie ma określonej z góry prawidłowej odpowiedzi, zamiast tego ma opisać wewnętrzne zależności między atrybutami.
Analiza koszykowa [15 minut]
Dane
Mamy dane następujące informacje o transakcjach w jednym z hipermarketów:
| Numer paragonu | Kupione produkty |
|---|---|
| 1000 | Ananas, Chleb, Drożdże |
| 2000 | Banan, Chleb, Eukaliptus |
| 3000 | Ananas, Eukaliptus, Chleb, Banan |
| 4000 | Banan, Eukaliptus |
Zadaniem algorytmu odkrywającego reguły asocjacyjne będzie odpowiedź napytanie: Jakie są zależności pomiędzy kupowanymi produktami?
Pytanie Patrząc na zbiór uczący w tabeli powyżej wypisz reguły które będą określać jakie produkty są kupowane najczęściej razem.
Support i Confidence
Z powyższego zbioru uczącego możemy łatwo wywnioskować następujące reguły:
if Banan then Eukaliptus if Eukaliptus then Banan if Ananas then Chleb if Chleb then Ananas
Pozostałe reguły intuicyjnie odrzuciliśmy ponieważ ich częstotliwość w zbiorze uczącym jest niewielka, i w związku z tym mamy małą pewność co do ich prawdziwości. W celu automatycznego określenia tych parametrów stosuje się dwa wskaźniki: support (wsparcie) i confidence (wiarygodność)
Support
Wskaźnik ten określa częstotliwość (prawdopodobieństwo) danej reguły w stosunku do wszystkich transakcji. Innymi słowy jest to stosunek ilości transakcji zawierających dane elementy wchodzące w skład reguły do wszystkich transakcji.
Dla przykładu z tabeli powyżej, support reguły
if Banan then Eukaliptus
jest równy  , ponieważ 3 transakcje zawierają Banan i Eukaliptus, natomiast ilość wszystkich transakcji jest równa 4.
, ponieważ 3 transakcje zawierają Banan i Eukaliptus, natomiast ilość wszystkich transakcji jest równa 4.
Pytanie Jaki jest support dla reguły poniżej?
if Ananas then Chleb
Confidence
Wskaźnik ten określa siłę implikacji w regule. Innymi słowy jest on definiowany jako stosunek ilości transakcji zawierających wszystkie elementy wchodzące w skład reguły do transakcji zawierających elementy z części warunkowej reguły.
Dla przykładu z tabeli powyżej, confidence reguły
If Banan then Eukaliptus
jest równy  , ponieważ 3 transakcje zawierają Banan i Eukaliptus, natomiast ilość transakcji zawierających elementy z części warunkowej tej reguły (czyli w tym wypadku Banan) jest także równa 3.
, ponieważ 3 transakcje zawierają Banan i Eukaliptus, natomiast ilość transakcji zawierających elementy z części warunkowej tej reguły (czyli w tym wypadku Banan) jest także równa 3.
Pytanie Jaki jest confidence dla reguł poniżej?
if Chleb then Ananas if Ananas then Chleb
Frequent Itemsets
Patrząc na przykłady powyżej odnalezienie dobrych reguł asocjacyjnych sprowadza się tak naprawdę do wykonania dwóch kroków
- wyszukania zbiorów elementów które mają support większy lub równy jakiemuś zadanemu supportowi progowemu - są tak zwanymi zbiorami częstymi (frequent itemsets)
- wybrania spośród nich tych konfiguracji, których confidence przekracza jakiś zadany confidence progowy.
W przypadku reguł asocjacyjnych, zbiory które zawierają k elementów nazywane są k-zbiorami (k-itemsets).
Pytanie Zakładając, ze bazujemy na danych z tabeli na początku sekcji Analiza koszykowa, wyznacz wszystkie 1-zbiory i policz dla nich support.
Przyjmując, że support progowy jest równy 50%, wyznacz 1-zbiór częsty.
Algorytm Apriori [10 minut]
Na zasadzie opisanej powyżej działa najpopularniejszy algorytm wyszukujący reguły asocjacyjne - algorytm Apriori. Wykonuje on następujące krok:
- znajdź wszystkie 1-zbiory (1-itemsets)
- znajdź pośród wygenerowanych 1-zbiorów, częste 1-zbiory (frequent 1-itemsets
 ) - czyli takie, których support jest
) - czyli takie, których support jest 
- bazując na wygeneruj 2-zbiory (2-itemsets)
- znajdź pośród wygenerowanych 2-zbiorów, częste 2-zbiory

- Powtarzaj proces, do momentu aż ostatni wygenerowany zbiór

Poniżej znajduje się bardziej formalny opis algorytmu:
![$$\begin{align}
& \mathrm{Apriori}(T,\epsilon)\\
&\qquad L_1 \gets \{ \mathrm{1-item sets} \} \\
&\qquad k \gets 2\\
&\qquad\qquad \mathrm{\textbf{while}}~ L_{k-1} \neq \ \emptyset \\
&\qquad\qquad\qquad C_k \gets \{ a \cup \{b\} \mid a \in L_{k-1} \land b \in \bigcup L_{k-1} \land b \not \in a \}\\
&\qquad\qquad\qquad L_k \gets \{ c \mid c \in C_k \land ~ \mathit{support}[c] \geq \epsilon \}\\
&\qquad\qquad\qquad k \gets k+1\\
&\qquad\qquad \mathrm{\textbf{return}}~\bigcup_k L_k
\end{align}$$](/lib/exe/fetch.php?media=wiki:latex:/img70da14b3526a2ce158df8a1eded01e16.png "Equation")
Dla ułatwienia, poniżej znajduje się rysunek pokazujący jak powinien działać algorytm na danych z tabeli na początku sekcji Analiza koszykowa1)
Uwaga 1: Na rysunku nie są przedstawione wszystkie k-zbiory częste.
Uwaga 2: Algorytm przedstawiony na rysunku poniżej zawiera pewną optymalizację polegająca na obserwacji, że zbiór 3-elementowy nie może być częsty jeśli zawiera w sobie zbiór dwuelementowy, który nie jest częsty.

Apriori i Weka
Weka zawiera implementację algorytmu Apriori, którą teraz przetestujemy na następującym zestawie transakcji:
| Paragon | Zakupy |
|---|---|
| 1 | A,B,C,D,G,H |
| 2 | A,B,C,D,E,F,H |
| 3 | B,C,D,E,H |
| 4 | B,E,G,H |
| 5 | A,B,D,E,G,H |
| 6 | A,C,F,G,H |
| 7 | B,D,E,G,H |
| 8 | A,C,D,E,G,H |
| 9 | B,C,D,E,H |
| 10 | A,C,E,F,H |
| 11 | C,E,H |
| 12 | A,D,E,F,H |
| 13 | B,C,E,F,H |
| 14 | A,B,C,F,H |
| 15 | A,B,E,F,H |
Zadania:
- Na początek należy przygotować odpowiedni plik Weki
- jak myślisz, w jaki sposób najlepiej zakodować informacje?
- możesz wzorować się na plikach z poprzedniego laboratorium data.tar.gz
- Możesz skorzystać z gotowego pliku umieszczonego tutaj: apriori-zakupy.arff.zip
- Wczytaj plik do Weki, przejdź do zakładki Associate i uruchom algorytm z domyślnymi ustawieniami. Jakie wyniki się pojawiły?
- Pobaw się ustawieniami algorytmu (aby wejść w ustawienia kliknij w wiersz z nazwą algorytmu i jego parametrami): Czy wiesz jak wyświetlić informację o znalezionych k-zbiorach? Czy wiesz jak zmienić oczekiwany poziom supportu i confidence? Czy rozumiesz pozostałe parametry? Sprawdź jak one wpływają na otrzymywane wyniki.
Duży przykład [15 minut]
W zestawie danych data.tar.gz znajduje się plik supermarket.arff – zawiera informacje o prawdziwych zakupach z jednego z supermarketów w Nowej Zelandii. Otwórz go w Wece i odpowiedz na następujące pytania:
- Ile jest atrybutów i co one reprezentują?
- Ile jest instancji i co one reprezentują?
- W zakładce Preprocess kliknij Edit… i przyjrzyj się danym: jakie wartości przyjmują atrybuty? Czy wszystkie wartości są uzupełnione?
- Jakie są 3 produkty najczęściej kupowane w tym sklepie? Jak to sprawdzić w zakładce Preprocess, a jak to sprawdzić za pomocą algorytmu Apriori wbudowanego w Wekę?
- Uruchom algorytm Apriori przy domyślnych ustawieniach. Następnie uruchom algorytm Apriori przy domyślnych ustawieniach dla tego samego zbioru danych, w którym zamiast brakujących wartości są wartości
n: supermarket-nonmiss.arff.zip. Porównaj otrzymane wyniki. - Następnie zrób takie samo porównanie dla danych z tabeli w sekcji Apriori i Weka. Jeden plik został przygotowany przez Ciebie już wcześniej - do porównania należy przygotować jeszcze drugi plik tak, aby jeden z nich zawierał wartości nie/fałsz, a drugi nieokreślone. Porównaj otrzymane wyniki.
- Po zapoznaniu się z wynikami, podaj co najmniej jeden argument za stosowaniem wartości nieokreślonej i co najmniej jeden za stosowaniem wartości nie/fałsz.
Pytania:
- W ramach laboratorium rozważaliśmy tworzenie reguł asocjacyjnych w analizie koszykowej, czyli ustalaliśmy jakie produkty są ze sobą najczęściej łączone w trakcie zakupów. Do czego może się przydać taka wiedza? Wymyśl dwa zastosowania.
- Do czego innego może przydać się tworzenie reguł asocjacyjnych? Wymyśl dwa problemy / pytania (niezwiązane z zakupami), na które można znaleźć dzięki nim odpowiedź.
3 Klasteryzacja
Klasteryzacja to przykład klasyfikacji. Podobnie jak w drzewach decyzyjnych z poprzedniego laboratorium, podejmujemy decyzję o określeniu przynależności elementu do jednej z grup. Tutaj jednak nie mamy z góry określonych kategorii, a są one tworzone na podstawie dostępnego zbioru danych uczących.
Istnieją różne rodzaje klastrów:
- Klastry rozłączne (np. algorytm K-Means/X-Means w dalszej części laboratorium):
- Klastry nachodzące na siebie (np. algorytm EM w dalszej części laboratorium):

- Klastry probabilistyczne (np. algorytm EM w dalszej części laboratorium):

- Klastry hierarchiczne:




Algorytm K-Means [20 minut]
Algorytm K-Means to prosty algorytm bez nauczyciela dzielący zbiór uczący na K klastrów zawierających podobne elementy (podobieństwo jest tutaj określone jako bliskość w przestrzeni elementów). Każdy z klastrów reprezentowany jest przez punkt (centroid) określający położenie środka klastra. Wyznaczanie centroidów przebiega zgodnie z następującymi krokami:
- Wylosuj K punktów (centroidów) w przestrzeni elementów.
- Oblicz odległość każdego z elementów od centroidów i przypisz ten element do najbliższego z nich.
- Zaktualizuj położenie każdego centroidu ustawiając go jako średnią wszystkich punktów, które są do niego przypisane.
- Powtarzaj kroki 2-3 aż do uzyskania zbieżności (przesunięcie centroidów w kroku 3 będzie mniejsze od ustalonego progu).
Nie ma tutaj zewnętrznego nauczyciela, wobec tego należy przyjąć inną strategię oceny poprawności rozwiązania – jedną z najprostszych możliwości jest tutaj policzenie sumy kwadratów odległości pomiędzy elementami i ich centroidami. W ten sposób promowane są rozwiązania, w których odległości są mniejsze, a co za tym idzie – elementy rzeczywiście są (względnie) blisko siebie.
Działanie algorytmu zaobserwuj w praktyce przy użyciu narzędzia http://krzysztof.kutt.pl/didactics/psi/kmeans/. Dokonaj klasteryzacji kilka razy (losowanie nowych danych za pomocą New points, losowanie nowych centroidów za pomocą New centroids, kolejne kroki za pomocą przycisku Find closest centroid/Update centroid) w różnych warunkach:
- ilość centroidów = ilość klastrów
ilość centroidów < ilość klastrów
ilość centroidów > ilość klastrów - dane zgrupowane (suwak w lewej połowie)
dane losowe (suwak w prawej połowie)
Pytania:
- Jak szybko algorytm osiąga zbieżność?
- Jak algorytm działa w przypadku losowych danych?
- Co dzieje się w sytuacji gdy ilość centroidów nie zgadza się z ilością klastrów ukrytych w danych?
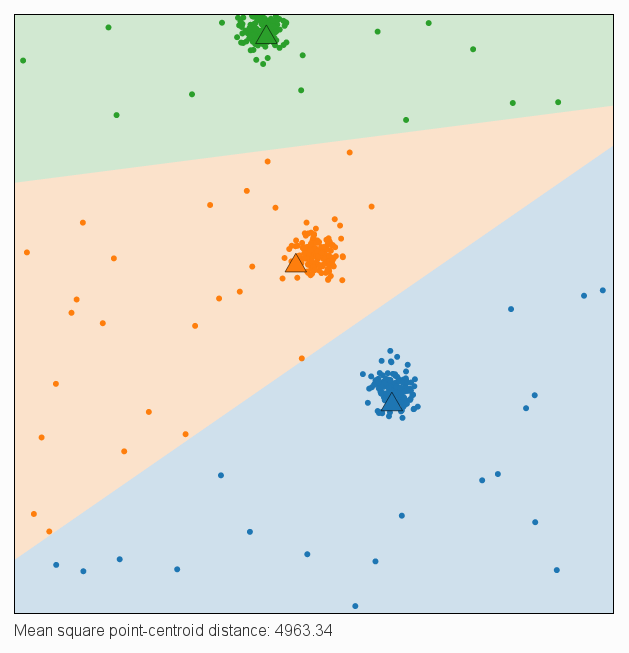
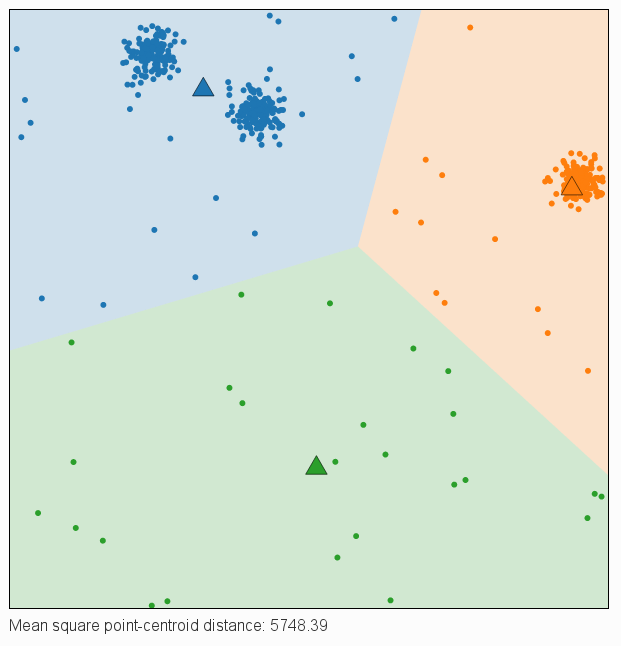
- Jaka jest skuteczność tego algorytmu w wykrywaniu klastrów ukrytych w danych? Jeżeli dane układają się w n klastrów i zadajemy n centroidów to czy zawsze udaje się dobrze dopasować dane? Porównaj poniższe dwa rysunki:


Jeżeli chcesz się jeszcze pobawić algorytmem K-Means, możesz skorzystać z apletu http://www.naftaliharris.com/blog/visualizing-k-means-clustering/, który pozwala między innymi na ręczne zaznaczanie początkowych położeń centroidów. Have fun ![]()
K-Means i Weka
Otwórz w Wece plik iris.arff z zestawu danych data.tar.gz. Wykorzystywaliśmy już ten plik na poprzednim laboratorium - opisuje on parametry kwiatów należących do trzech gatunków Irysów:

Zadania:
- Przypomnij sobie jak zbudowany jest ten plik: ile jest atrybutów, jakich są typów, ile jest instancji. Zapoznaj się z budową zboru uczącego: kliknij
Edit…w zakładce Preprocess. Zauważ, że dane są podzielone względem klas: najpierw 50 instancji jednej klasy, następnie 50 instancji drugiej i na końcu 50 instancji trzeciej klasy. - Przejdź na zakładkę Visualize i zapoznaj się z rozkładem danych:
- Są to trójwymiarowe wykresy bazujące na trzech wybranych atrybutach ze zbioru danych: oś X, oś Y i różne kolory - upewnij się, że kolorem oznaczony jest atrybut class (domyślnie).
- Kliknięcie na wykres pozwala na jego powiększenie (na powiększeniu można manipulować atrybutami położonymi na osiach).
- Wyobraź sobie sytuację, w której znika atrybut
class(znikają kolory) – czy jesteś w stanie ponownie pogrupować te dane w pierwotne klasy? - Spróbujmy to zrobić za pomocą algorytmu K-Means zaimplementowanego w Wece:
- Przejdź do zakładki Cluster.
- Zostaw domyślną wartość
Cluster mode=Use training set - Wybierz algorytm SimpleKMeans, w ustawieniach zmień liczbę klastrów na 3 i uruchom go.
- Zapoznaj się z wynikami:
- Z wyświetlonym raportem
- Z wizualizacją: kliknij prawym na wynik klasteryzacji w
Result listi z menu wybierzVisualize cluster assignments - Przede wszystkim zapoznaj się z wizualizacją: X = Class, Y = Cluster. Możesz jeszcze pobawić się suwakiem
Jitter, który rozrzuca dane (bo wiele punktów znajduje się w tym samym miejscu). - Czy dane zostały poprawnie zaklasyfikowane? Jaki błąd popełniliśmy?
- Spróbujmy to zrobić po raz kolejny:
- Kliknij przycisk
Ignore attributes, zaznacz odpowiedni atrybut (który?) i kliknijSelect. Uruchom ponownie klasteryzację. - Zapoznaj się z wynikami i porównaj je z uzyskanymi wcześniej. Jaka teraz była skuteczność klasyfikacji?
- Czy wiesz który z trzech gatunków Irysów został w 100% poprawnie zaklasyfikowany przez ten algorytm? Możesz to odczytać z wykresu wizualizującego wyniki klasyfikacji, jak również możesz w
Cluster modezaznaczyć opcjęClasses to clusters evaluation. Po wybraniu tej opcji i wyświetleniu wizualizacji możesz zobaczyć na wykresie krzyżyki (poprawne trafienia) i kwadraty (niepoprawne klasyfikacje).
- Przeprowadź klasteryzację po raz trzeci. Tym razem nie zmieniaj żadnych ustawień. Czy pojawiły się dokładnie takie same wyniki?
- Jak to było wcześniej powiedziane, algorytm K-Means losuje początkowe położenie centroidów, więc wyniki powinny się od siebie różnić. Tutaj jednak są takie same…
- W jaki sposób sprawić aby wylosowały się inne wyniki?
Inne algorytmy klasteryzacji [10 minut]
Algorytm X-Means
Algorytm K-Means jest bardzo popularny, ale ma kilka wad, m.in. nie jest w pełni automatyczny – użytkownik musi samodzielnie określić liczbę klastrów. Co jednak w sytuacji kiedy nie chcemy albo nie możemy tego zrobić (po prostu nie wiemy ile takich klastrów będzie)? Przygotowane zostało rozszerzenie algorytmu K-Means o m.in. automatyczne wyznaczanie ilości klastrów (w przedziale określonym przez użytkownika). Algorytm ten to X-Means i działa on wykonując następujące kroki:
- Rozpoczęcie algorytmu z najmniejszym dozwolonym przez użytkownika K.
- Ulepszanie parametrów – wykonywanie algorytmu K-Means dla aktualnego K aż do uzyskania zbieżności.
- Ulepszanie struktury – podzielenie wybranego centroidu na dwa centroidy i wykonanie kroku 2 aż do uzyskania zbieżności. Jeżeli wynik jest lepszy (zgodnie z przyjętą metryką) to go akceptujemy i zwiększamy K o 1. Jeśli nie – próbujemy podzielić inny centroid.
- Wykonujemy kroki 2-3 aż do momentu kiedy podział nie ulepsza rozwiązania / K osiągnie maksymalną dozwoloną wartość.
Zadania:
- Wczytaj ponownie plik
iris.arffdo Weki. - W zakładce Cluster wybierz algorytm
XMeansi uruchom go na domyślnych ustawieniach.- Algorytm XMeans operuje tylko i wyłącznie na atrybutach numerycznych. Dlatego aby go włączyć należy: (a) albo w
Ignore attributeswybraćclass, (b) albo wybrać opcjęClasses to clusters evalutaion.
- Zapoznaj się z otrzymanymi wynikami:
- Ile klastrów pojawiło się w wynikowym modelu?
- Przeanalizuj wizualizację wyników.
- Porównaj otrzymane wyniki z wynikami z K-Means.
- Zapoznaj się z dostępnymi opcjami i ich znaczeniem. Poeksperymentuj z różnymi ustawieniami.
Algorytm EM
Algorytmy K-Means i X-Means jednoznacznie dzielą przestrzeń przykładów na odpowiednią liczbę klastrów. Każdy z klastrów reprezentowany jest przez położenie centroidu, a element należy do tego klastru, którego centroid znajduje się najbliżej.
W algorytmie EM (Expectation-Maximization) klastry reprezentowane są przez średnie (będące odpowiednikami centroidów) oraz odchylenia standardowe. Dzięki temu możliwe jest określenie prawdopodobieństwa przynależności elementu do każdego klastru i wybranie tego o największej wartości (nie jest to więc „sztywny” jednoznaczny podział jak w K-Means tylko „miękki”).
Działanie algorytmu może być różne w zależności od implementacji, ale w ogólnym wypadku wygląda analogicznie jak w przypadku algorytmu K-Means i zostało zobrazowane na poniższym gifie:

Zadania:
- Wczytaj ponownie plik
iris.arffdo Weki. - W zakładce Cluster wybierz algorytm
EMi uruchom go na domyślnych ustawieniach. - Zapoznaj się z otrzymanymi wynikami:
- Ile klastrów pojawiło się w wynikowym modelu? Na domyślnych ustawieniach algorytm EM sam ustala optymalną liczbę klastrów - czy wiesz jak to zmienić?
- Przeanalizuj wizualizację wyników.
- Porównaj otrzymane wyniki z wynikami z K-Means i X-Means.
- Zapoznaj się z dostępnymi opcjami i ich znaczeniem. Poeksperymentuj z różnymi ustawieniami.
4 Poprawność klasyfikacji [10 minut]
Pytania:
- Załaduj plik
credit-g.arffdo Weki. Zawiera on dane uczące dla systemu, który na podstawie atrybutów zawartych w pliku powinien określać czy dany zestaw wartości atrybutów wskazuje na wiarygodnego klienta banku, czy też nie - czy można przyznać mu kredyt, czy jest to ryzykowne. - Przejdź do zakładki Classify i wybierz algorytm J48.
- W obszarze Test options wybierz opcje Percentage split z wartością 66% Oznacza to, ze 66% danych posłuży do uczenia, a 34% do walidacji. Jakie to ma znaczenie?
- Uruchom algorytm. Ile procent przypadków zostało poprawnie zaklasyfikowanych? Czy to dobry wynik?
- Zmień klasyfikator na ZeroR z gałęzi rules. Jakie są wyniki?
- Wybierz trzy inne klasyfikatory i je wypróbuj. Jakie dają wyniki?
- Przejdź do zakładki Preprocess i zobacz jak wygląda rozkład atrybutu określającego czy danych zestaw jest dobry czy zły. Jaka byłaby skuteczność algorytmu który niezależnie od wartości atrybutów „strzelałby” że użytkownik jest wiarygodny?
- Dlaczego przed przystąpieniem do klasyfikacji, warto wcześniej przyjrzeć się danym?

5 Większy zbiór danych [10 minut] (o ile wystarczy czasu)
Wybierz jeden zbiór danych:
- wine.arff.zip – dane dotyczące win otrzymywanych w jednym regionie Włoch z trzech różnych odmian winorośli (13 atrybutów, 178 instancji, 3 klastry)
- vehicle.arff.zip – parametry pojazdów wyciągnięte ze zrobionych zdjęć (18 atrybutów, 846 instancji, 4 klastry)
- spambase.arff.zip – dane opisujące wiadomości e-mail z klasyfikacją spam/nie spam (57 atrybutów, 4 601 instancji, 2 klastry)
- letter.arff.zip – parametry opisujące wielkie litery napisane różnymi czcionkami (16 atrybutów, 20 000 instancji, 26 klastrów)
Ściągnij go i pobaw się nim z użyciem metod, które pojawiły się na aktualnym i poprzednim laboratorium, np.:
- sprawdź skuteczność klasteryzacji,
- poszukaj ukrytych zależności między różnymi parametrami (z wykorzystaniem reguł asocjacyjnych),
- ustal czy da się stworzyć dobre drzewo decyzyjne dla danego przykładu,
- spróbuj wyznaczyć model liniowy, który najlepiej opisuje zadany problem.

Chcesz wiedzieć więcej?
- K-Means++ – inne ulepszenie algorytmu K-Means niż przedstawione X-Means
Machine Learning ogólnie
- Ten Machine Learning Algorithms You Should Know to Become a Data Scientist (z linkami do bibliotek i tutoriali)
- The Guerrilla Guide to Machine Learning with Python („a complete course for the quick study hacker with no time (or patience) to spare”)
- Kursy z uczenia maszynowego na Coursera.org:
- https://www.coursera.org/learn/machine-learning - podstawy matematyczne, zadania programistyczne (budowanie metod od podstaw; Octave/Matlab), świetny wykładowca!
- https://www.coursera.org/specializations/machine-learning - podstawy praktyczne: przegląd przez różne metody i przykłady ich zastosowań w rzeczywistości, zadania programistyczne (Python, wykorzystanie gotowych bibliotek do uczenia maszynowego)
- Deep Learning:
- Konkursy na najlepszy algorytm predykcyjny:
-
- Narzędzia:
- Kursy Weki: jak korzystać z narzędzia, jakie ma możliwości, jak rozumieć wyniki?
- Use cases: