Statistical Relational AI
Statistical Relational AI (StaRAI) is a branch of Artificial Intelligence lying at the intersection between statistical and logical methods, applied to relational data.
This class will cover the most common types of tasks considered by the StaRAI methods.
Materials used in the class come from a workshop conducted by Marco Lippi at ACAI'2018 summer school in Ferrara.
Questions:
What is hidden under the term “relational data”?
Could modern “deep” learning methods work be used in the same context?
Link Prediction
Given a relational model of a domain (e.g. graph of connections in the social network) we have to learn how to predict connection between nodes in similar networks.
Questions:
What types of networks can we spot in real life?
What are the possible applications of the link predictor?
What does “similar network” mean? How can we validate the predictor?
What learning features can be found in the network?
Toy Problem
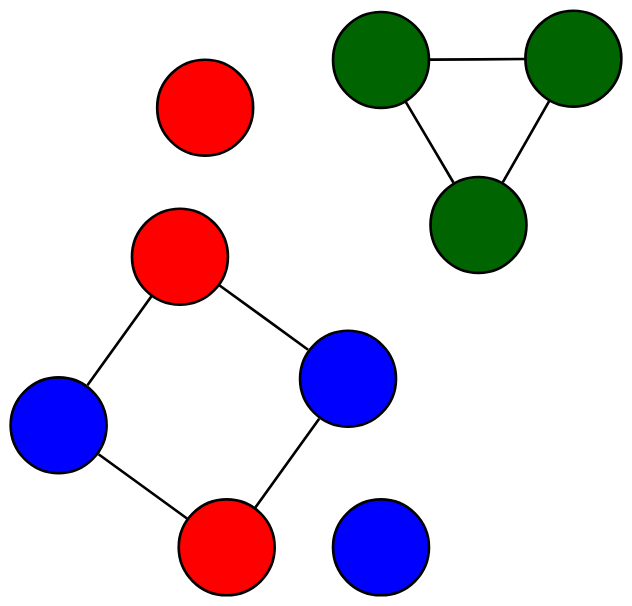 Let assume we have a very tiny network, similar to the one shown on the right. In this problem all links are undirected and unlabeled. Nodes have labels shown using different colors.
Our ask is to train a link predictor using Problog. In case somebody forgot Problog installation is fairly easy given a working Python environment (
Let assume we have a very tiny network, similar to the one shown on the right. In this problem all links are undirected and unlabeled. Nodes have labels shown using different colors.
Our ask is to train a link predictor using Problog. In case somebody forgot Problog installation is fairly easy given a working Python environment (pip install problog and optionally problog install on Linux). In case it wasn't simple enough, one can try to use the on-line interface. The evidence file for the problem can downloaded from this link.
You can start from this point.
Questions:
How would you write a Problog model for this task?
Do you find this kind of predictor satisfying? Would you call it “relational”?
Entity Classification
Another problem is to classify entities in the network, e.g. given a social graph, guess gender of the people involved.
Question:
What are the possible applications of such classificator?
Toy Problem
Given a hypertext documents (or simply: linked text documents) classify them by the topic. Read the Problog model below:
0.5::topic(P,sport) :- hasword(P,game).
0.7::topic(P,food) :- hasword(P,bread).
0.9::topic(P,food) :- link(P,Q), topic(Q,food).
hasword(p1,bread).
hasword(p2,game).
hasword(p3,coffee).
link(p3,p1).
evidence(topic(p2,sport)).
Questions
What network's features have impact on the result?
Try to learn a similar (but bigger) model from the following evidence
data and
network definition. Is there any issue with creating such a model?
Could you learn similar classifier using classic machine learning classifiers?
Let's make the toy problem a bit more interesting and create a basic search engine. Download and read a following file that contains a basic set of data about an information retrieval scenario.
Questions
What has to be changed in our classifier to make it a basic search engine?
Learn model parameters from scratch, using the file you have downloaded previously.
Intermission: Why?
Before moving to the next topic, let us analyze what good have we done.
What have our programs learned? What's the output?
What data had to be provided? What's the input?
Is there any advantage over other methods you know? Is there any disadvantage?
Structure Learning
Sometimes we do not have domain knowledge - sometimes we analyze just chaotic data we can make no sense at all. Sometimes we need so called structure learning - algorithm learning not only parameters but also structure of the model.
Questions:
What applications of structure learning can you imagine?
Do you know any related problems/methods?
Quick ProbFOIL Tutorial
ProbFOIL is a probabilistic version of the famous FOIL induction system, that can learn problog models from data.
It is based on Problog and installation is analogous (pip install probfoil).
The input of ProbFOIL consists of two parts: settings and data. These are both specified in Prolog (or ProbLog) files, and they can be combined into one.
The data consists of (probabilistic) facts. The settings define
target: the predicate we want to learn
modes: which predicates can be added to the rules
types: type information for the predicates
other settings related to the data
To use:
probfoil data.pl
Multiple files can be specified and the information in them is concatenated. (For example, it is advisable to separate settings from data).
Several command line arguments are available. Use –help to get more information.
Target
The target should be specified by adding a fact
learn(predicate/arity).
Modes
The modes should be specified by adding facts of the form
mode(predicate(mode1, mode2, ...).
, where modeX is the mode specifier for argument X. Possible mode specifiers are:
+: input - the variable at this position must already exist when the literal is added
-: output - the variable at this position does not exist yet in the rule (note that this is stricter than usual)
c: constant - a constant should be introduced here; possible value are derived automatically from the data
Types
For each relevant predicate (target and modes) there should be a type specifier. This specifier is of the form
base(predicate(type1, type2, ...).
, where typeX is a type identifier. Type can be identified by arbitrary Prolog atoms (e.g. person, a, etc.)
Example generation
By default, examples are generated by quering the data for the target predicate. Negative examples can be specified by adding zero-probability facts, e.g.:
0.0::grandmother(john, mary).
Alternatively, ProbFOIL can derive negative examples automatically by taking combinations of possible values for the target arguments. Note that this can lead to a combinatorial explosion. To enable this behavior, you can specify the fact
example_mode(auto).
Example
Try to learn model from the following file:
% Modes
mode(male(+)).
mode(parent(+,+)).
mode(parent(+,-)).
mode(parent(-,+)).
% Type definitions
base(parent(person,person)).
base(male(person)).
base(grandmother(person,person)).
% Target
learn(grandmother/2).
% How to generate negative examples
example_mode(auto).
You'll have to define a family using male and parent facts.
Start with simple family and then add new members as needed.
Big Fat Assignment
Try to learn structure of the Information Retrieval model, you've done earlier by hand.
Is the learned model satisfying? If not, what is the problem? Try to fix it by changing learning data by hand.
Modify model to consider more than only one query. What has to be changed?
