To jest stara wersja strony!
NoSQL
Ruch NoSQL promuje klasę nierelacyjnych baz jako alternatywę dla tradycyjnych baz relacyjnych, nazywając je czasami bazami następnej generacji. Bazy te unikają poleceń JOIN, nie posiadają sztywnych schematów oraz cechują się dobrą skalowalnością.
Oto kilka rozwiązań zaproponowanych przez ruch NoSQL:
MongoDB
MongoDB to bardzo wydajna i skalowalna baza danych, zorientowana na przechowywanie dokumentów z pominięciem schematów. Projekt został wydany na licencji AGPL w wersji 3 i możemy go używać w aplikacjach biznesowych.
MongoDB jest bazą nowej generacji, która jest zorientowana na przechowywanie dokumentów JSON, o dowolnej strukturze. Dokumenty te są przechowywane wewnętrznie jako BSON – Binary JSON. Całość została napisana w języku Cpp. Bazę stworzono z myślą o pracy w dużych obciążeniach oraz posiada wbudowane mechanizmy skalowania i replikacji W przypadku instalacji 32-bitowej rozmiar pojedynczej bazy danych jest ograniczony do około 2GB.
MongoDB składa się z trzech komponentów:
Dostęp do bazy możliwy jest przy wykorzystaniu sterowników, które oficjalnie w tej chwili są dostępne dla języków:
C
Cpp
Java
JavaScript
Perl
PHP
Python
Ruby
oraz poprzez sterowniki nieoficjalne, które wspierają:
REST
C# i .NET
Clojure
ColdFusion
Delphi
Erlang
Factor
Fantom
F#
Go
Groovy
Haskell
Lua
Node.js
PowerShell
Scala
Scheme
Smalltalk
Analogie do baz SQL
| MongoDB | BazaSQL |
| Dokument | Wiersz / Rekord |
| Kolekcja | Tablica |
| _id | Klucz główny |
| Zagnieżdżenie | Relacja 1:N |
| Tablica referencji do obiektów | Relacja M:N |
| Indeks | Indeks |
Baza dokumentowa
W bazach zorientowanych na dokumenty, dane nie są przechowywane w tabelach o z góry założonej strukturze i takich samych polach dla każdego rekordu. Każdy dokument może mieć różne pola, a dane w każdym polu mogą być zbiorem innych danych. Puste pola nie są w dokumencie w ogóle przechowywane, dzięki czemu ich nagłówki nie marnują miejsca w bazie.
Przykład:
FirstName="Bob", Address="5 Oak St.", Hobby="sailing"
FirstName="Jonathan", Address="15 Wanamassa Point Road", Children=("Michael,10", "Jennifer,8", "Samantha,5", "Elena,2").
BSON pozwala również na przechowywane plików binarnych.
Oto prosty przykład reprezentacji tych samych danych w formacie XML:
<?xml version="1.0" encoding="utf-8"?>
<dane>
<user>
<imie>jan</imie>
<nazwisko>Kowalski</nazwisko>
</user>
<user>
<imie>Piotr</imie>
<nazwisko>Nowak</nazwisko>
</user>
</dane>
oraz JSON:
{
"dane" : {
"user" : [
{
"imie" : "Jan",
"nazwisko" : "Kowalski"
},
{
"imie" : "Piotr",
"nazwisko" : "Nowak"
}
]
}
}
Instalacja na systemie Windows
-
Ściągamy binarną wersję MongoDB odpowiednio:
Wypakowujemy ściągnięty plik do wybranej przez nas lokalizacji.
Tworzymy foldery w których MongoDB będzie przechowywać dane. MongoDB nie stworzy tych folderów automatycznie, więc musimy to zrobić ręcznie. W katalogu głównym dysku, na który wypakowaliśmy ściągnięty wcześniej plik MongoDB, tworzymy następujące foldery:
Uruchomienie i połączenie z serwerem.
Podczas pierwszego uruchomienia korzystamy z plików: mongod.exe oraz mongo.exe, które znajdują się w folderze bin w miejscu gdzie wypakowaliśmy binarną wersję MongoDB.
Najpierw uruchamiamy plik mongod.exe, czyli serwer bazodanowy, a następnie mongo.exe czyli powłokę administracyjną.

Jak widać nie musimy sami tworzyć bazy. Zostanie ona utworzona automatycznie, po dokonaniu pierwszego wpisu.
GridFS
MongoDB pozwala na przechowywanie plików binarnych. Rozmiar obiektów BSON jest ograniczony do 4 MB. GridFS dostarcza mechanizmu, który pozwala na podzielenie dużych plików pomiędzy kilka dokumentów. Dzięki temu możemy przechowywać większe pliki np.: filmowe w bazie, a przy okazji dostępne są operacje działające na podanym przez nas zakresie np.: możemy pobrać pierwsze N bajtów pliku.
Replikacja
MongoDB wspiera replikację danych pomiędzy serwerami dla zapewnienia redundancji oraz zwiększenia niezawodności. MongoDB powinien zawsze być rozlokowany na co najmniej dwóch serwerach: master i slave.
Master może odczytywać i zapisywać, a slave kopiuje od niego dane i może być użyty tylko do odczytu i kopii bezpieczeństwa.
Przykład uruchomienia pary master i slave lokalnie:
nazwy katalogów możemy oczywiście podać dowolne pod warunkiem, że ustawimy odpowiednie ścieżki jako parametry przy wywołaniu pliku mongod.exe.
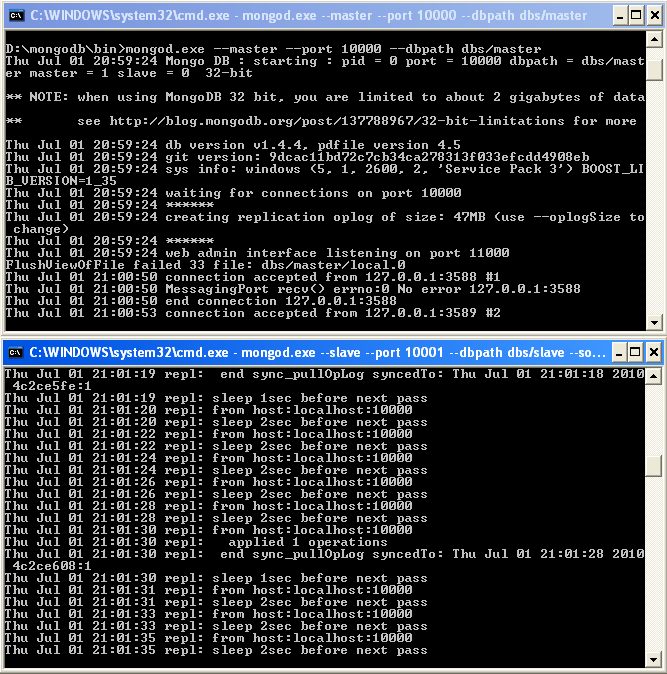
Jeżeli jakieś operacje zostaną wykonane na serwerze master, serwer slave zreplikuje wszelkie zmiany w danych.
Sharding
MongoDB skaluje się poziomo, co znaczy że wykorzystuje siłę przetwarzania rozproszonego. System zwany shadringiem, jest podobny do BigTable and PNUTS. Dane są dzielone i zostają rozdystrybuowane pomiędzy kilka shardów (shard jest to serwer master z co najmniej jednym serwerem slave). Dla aplikacji nie ma różnicy czy komunikuje się z sharem czy też z pojedynczą bazą danych, ponieważ wszystkie żądania przechodzą przez proces z nazwie mongos. Proces ten wie, jakie dane znajdują się na jakim shadrze i przekierowuje odpowiednio żądanie klienta.
Sharding automatycznie dostosowuje zmiany odnośnie obciążenia i dystrybucji danych pomiędzy klastrami oraz zapewnia mechanizm fail-over. Dzięki temu, że każdy shard zawiera jakąś ciągłą porcję danych z konkretnej kolekcji, mamy bardzo szybki dostęp do danych oraz możemy czytać równolegle z różnych serwerów. Skalowalność takiej bazy danych jest praktycznie nielimitowana, co jest wręcz niemożliwe do osiągnięcia przy typowych RDBS. MongoDB świetnie nadaje się do pracy w chmurze, jest jednym z rozwiązań, które może naśladować googleowe BigTable czy amazonowe SimpleDB.
Do równoległego przetwarzania danych przygotowano mechanizm Map/Reduce, który umożliwia wykonywanie równoległych zapytań, sortowanie i dokonywanie innych operacji na kolekcjach.
Podstawy korzystania z shella mongo
uruchamiamy powłokę shellową tak jak to zrobiliśmy w punkcie numer 5. Domyślnie zostaniemy połączeni z bazą „test” na hoście lokalnym.
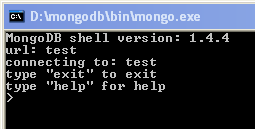
„connecting to:” wskazuje nam nazwę bazy z której korzysta shell. Aby zmienić bazę danych wpisujemy np.:
> use mydb
switched to db mydb
wpisując powyższe polecenie przeszliśmy z bazy o nazwie „test” do bazy „mydb”.
Przyglądając się następnym przykładom, warto zwrócić uwagę, że nigdy ręcznie nie tworzymy bazy danych lub kolekcji. MongoDB zajmie się tym za nas, zaraz po tym jak wydamy polecenie wstawienia danych do bazy. MongoDB stworzy bazę jeśli do tej pory taka nie istnieje i uzupełni ją danymi. Jeśli chcemy pobrać coś z kolekcji, która nie istnieje, MongoDB traktuje to jako pustą kolekcję.
Jeśli zmieniamy bazę danych korzystając z komendy use, to baza nie zostanie utworzona od razu, lecz przy pierwszym wstawieniu do niej informacji.
Aby wyświetlić już istniejące bazy danych korzystamy z polecenia:
> show dbs
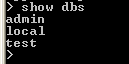
Wstawiane danych do kolekcji
Stworzymy teraz dwa obiekty: j oraz t, a następnie zapiszemy je w kolekcji things.
Utworzenie obiektu j:
j = { name : "mongo" };
Utworzenie obiektu t:
t = { x : 3 };
Zapisanie obiektu j w kolekcji things:
db.things.save(j);
Zapisanie obiektu t w kolekcji things:
db.things.save(t);
Wypisanie zawartości kolekcji things:
db.things.find();
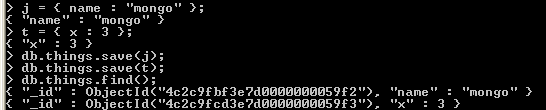
możemy również dodać większą ilość danych za pomocą pętli for:
> for (var i = 1; i <= 20; i++) db.things.save({x : 4, j : i});
> db.things.find();
{ "_id" : ObjectId("4c2209f9f3924d31102bd84a"), "name" : "mongo" }
{ "_id" : ObjectId("4c2209fef3924d31102bd84b"), "x" : 3 }
{ "_id" : ObjectId("4c220a42f3924d31102bd856"), "x" : 4, "j" : 1 }
{ "_id" : ObjectId("4c220a42f3924d31102bd857"), "x" : 4, "j" : 2 }
{ "_id" : ObjectId("4c220a42f3924d31102bd858"), "x" : 4, "j" : 3 }
{ "_id" : ObjectId("4c220a42f3924d31102bd859"), "x" : 4, "j" : 4 }
{ "_id" : ObjectId("4c220a42f3924d31102bd85a"), "x" : 4, "j" : 5 }
{ "_id" : ObjectId("4c220a42f3924d31102bd85b"), "x" : 4, "j" : 6 }
{ "_id" : ObjectId("4c220a42f3924d31102bd85c"), "x" : 4, "j" : 7 }
{ "_id" : ObjectId("4c220a42f3924d31102bd85d"), "x" : 4, "j" : 8 }
{ "_id" : ObjectId("4c220a42f3924d31102bd85e"), "x" : 4, "j" : 9 }
{ "_id" : ObjectId("4c220a42f3924d31102bd85f"), "x" : 4, "j" : 10 }
{ "_id" : ObjectId("4c220a42f3924d31102bd860"), "x" : 4, "j" : 11 }
{ "_id" : ObjectId("4c220a42f3924d31102bd861"), "x" : 4, "j" : 12 }
{ "_id" : ObjectId("4c220a42f3924d31102bd862"), "x" : 4, "j" : 13 }
{ "_id" : ObjectId("4c220a42f3924d31102bd863"), "x" : 4, "j" : 14 }
{ "_id" : ObjectId("4c220a42f3924d31102bd864"), "x" : 4, "j" : 15 }
{ "_id" : ObjectId("4c220a42f3924d31102bd865"), "x" : 4, "j" : 16 }
{ "_id" : ObjectId("4c220a42f3924d31102bd866"), "x" : 4, "j" : 17 }
{ "_id" : ObjectId("4c220a42f3924d31102bd867"), "x" : 4, "j" : 18 }
has more
Napisem has more shell informuje nas o tym, że nie wszystkie dane zostały wyświetlone, aby przejrzeć kolejną część, musimy wpisać polecenie:
> it
{ "_id" : ObjectId("4c220a42f3924d31102bd868"), "x" : 4, "j" : 19 }
{ "_id" : ObjectId("4c220a42f3924d31102bd869"), "x" : 4, "j" : 20 }
Wyciąganie danych z bazy
Zagadnienie to jest łatwiej przedstawić na przykładach niż wyjaśnić, dlatego poniżej zostaną podane przykładowe zapytania napisane w języku SQL, a zaraz pod nimi sposób reprezentacji tego samego zapytania korzystając z MongoDB poprzez nakładkę shellową.
SELECT * FROM things WHERE name=„mongo”
> db.things.find({name:"mongo"}).forEach(printjson);
{ "_id" : ObjectId("4c2209f9f3924d31102bd84a"), "name" : "mongo" }
SELECT * FROM things WHERE x=4
> db.things.find({x:4}).forEach(printjson);
SELECT j FROM things WHERE x=4
> db.things.find({x:4}, {j:true}).forEach(printjson);
Jak widać zapis:
{ a:A, b:B, …}
oznacza:
„where a=A and b=B and …”
Pole _id jest generowane automatycznie i zwracane po każdym wykonaniu zapytania.
Funkcja findOne()
Funkcja findOne() przyjmuje te same parametry co funkcja find(), ale zwraca albo tylko pierwszy dokument zwrócony z bazy danych, albo null jeśli żaden dokument nie odpowiada zapytaniu.
Przykład:
> printjson(db.things.findOne({name:"mongo"}));
{ "_id" : ObjectId("4c2209f9f3924d31102bd84a"), "name" : "mongo" }
jest to ekwiwalent zapytania:
find({name:"mongo"}).limit(1);
Funkcja limit()
Funkcja limit() pozwala ograniczyć nam ilość zwróconych wyników. Jest szczególnie polecana, ze względów wydajnościowych. Pozwala ograniczyć pracę bazy danych i ogranicza liczbę danych przesyłanych przez sieć.
Oto przykład:
> db.things.find().limit(3);
{ "_id" : ObjectId("4c2209f9f3924d31102bd84a"), "name" : "mongo" }
{ "_id" : ObjectId("4c2209fef3924d31102bd84b"), "x" : 3 }
{ "_id" : ObjectId("4c220a42f3924d31102bd856"), "x" : 4, "j" : 1 }
Indeksy
Ciekawe funkcje pomocy




