Testy złożonych systemów i aplikacji wymagają zdefiniowania oraz weryfikacji ogromnej liczby przypadków testowych pokrywających wszystkie wymagania stawiane przez klienta. Aby umożliwić sprawne przeprowadzenie testów konieczne jest umiejętne zarządzanie zespołem testerów, a także dobra komunikacja w jego obrębie. Celem projektu jest stworzenie aplikacji internetowej, stanowiącej odpowiedź na tą potrzebę biznesową. Aplikacja ta ułatwi pracę zespołów zajmujących się testowaniem oprogramowania poprzez umożliwienie im wygodnego zarządzania wymaganiami i przypadkami testowymi oraz usprawnienie samego procesu wykonywania testów. Istotnym elementem aplikacji będzie również funkcjonalność zarządzania zespołem testerów, przydzielania im ról oraz zarządzania poziomem dostępu do poszczególnych projektów.
Projekt realizowany będzie przy współpracy z firmą ATSI S.A., zajmującą się tworzeniem oprogramowania. Wymiana doświadczeń z testerami pracującymi na co dzień z tego typu narzędziami pozwoli określić czego brakuje aktualnie dostępnym rozwiązaniom oraz zidentyfikować możliwości wprowadzenia nowych funkcjonalności, które pozytywnie wpłyną na użyteczność oprogramowania. W efekcie powstanie rozwiązanie stanowiące atrakcyjną alternatywę dla już istniejących.
Analiza stanu wyjściowego
Opracowanie projektowanej aplikacji wymaga dokładnej analizy środowiska, w którym przyjdzie jej działać. W ogólnym zarysie na środowisko to składa się wewnętrzna sieć firmy oraz wszystkie systemy i narzędzia wykorzystywane przez testerów, pracujące w tej sieci. Głównym przedmiotem naszego zainteresowania jest aktualnie wykorzystywane w firmie narzędzie wspomagające pracę testerów w zakresie definiowania wymagań, opisywania przypadków testowych i wykonywania testów. Narzędzie to nosi nazwę Testlink (http://www.teamst.org/) i jest aplikacją webową na licencji Open Source o bardzo rozbudowanej funkcjonalności. Do głównych zalet Testlinka należy zaliczyć dostępność API XML/RPC umożliwiającego pobieranie wyników testów oraz współpracę z wieloma systemami śledzenia błędów. Mimo powyższych zalet aplikacja Testlink posiada też kilka mankamentów, które sprawiają, że nie spełnia wszystkich wymagań klienta. Należy tutaj wymienić mało przyjazny dla użytkownika interfejs, narzucenie modelu procesu testowania niezgodnego z modelem stosowanym w firmie, a także brak integracji z narzędziami do automatyzacji testów.
Ważnymi elementami składowymi środowiska docelowego dla projektowanego oprogramowania są narzędzia takie jak Jira i Hudson. Ich obecność wymusza uwzględnienie na etapie projektowym rozwiązań, które pozwolą na zintegrowanie z nimi tworzonej aplikacji. Konieczne jest umożliwienie testerowi raportowania błędów do Jiry z poziomu aplikacji w przypadku wykrycia błędu podczas testowania, a także zapewnienie funkcjonalności łączenia przypadków testowych i wymagań z odpowiednimi testami automatycznymi wykonywanymi przez Hudsona.
Analiza wymagań użytkownika
Główne wymagania funkcjonalne systemu:
Zarządzanie projektami grupującymi wymagania i przypadki testowe dla pojedynczych produktów/modułów oprogramowania wytwarzanych przez firmę
Zarządzanie zespołem testerów dla danego projektu (dodawanie/usuwanie użytkowników z projektu)
Zarządzanie przypadkami testowymi i wymaganiami (CRUD)
Zarządzanie zestawami przypadków testowych i wymagań (CRUD)
Przypisywanie wymagań do użytkowników
Śledzenie dat i autorów ostatnich modyfikacji w przypadkach testowych i wymaganiach
Zarządzanie priorytetami przypadków testowych
Automatyczne blokowanie przypadków testowych na czas edycji
Integracja modułów zarządzania przypadkami testowymi i wymaganiami w celu umożliwienia tworzenia powiązań między nimi
Integracja aplikacji z narzędziem do śledzenia błędów Jira
Integracja z serwerem CI Hudson na potrzeby wykonywania testów automatycznych (w tym pobieranie rezultatów tych testów i uwzględnianie ich w raportach)
Generowanie raportów informujących o rezultatach testów i postępach prac nad projektem
Zarządzanie użytkownikami i ich grupami
Przypisywanie ról użytkownikom
Możliwość blokowania kont i resetowania haseł użytkowników
Zarządzanie profilem użytkownika
Panel zbiorczy z informacjami o ostatnich zmianach
Wyszukiwanie pełnotekstowe w opisach przypadków i wymagań
Wymagania związane z interfejsem użytkownika:
Łatwy w obsłudze interfejs (obsługa drag & drop, multiselect, menu kontekstowe, wygodna nawigacja- pasek umożliwiający szybkie przejście do poprzedniego widoku, menu główne udostępniające najważniejsze funkcje)
Sortowanie tabeli przypadków testowych i wymagań
Walidacja formularzy
Powiadomienia o zmianach w wymaganiach dotyczących danego przypadku testowego
Kopiowanie przypadków testowych i wymagań
Wydruk przypadków testowych i wymagań
Określenie przypadków oraz scenariuszy użycia
Konto użytkownika:
Rejestracja użytkownika w systemie - nowy użytkownik wchodzi na stronę główną aplikacji, przechodzi do panelu rejestracji i wypełnia standardowy formularz rejestracji, podając takie informacje jak: imię, nazwisko, login, hasło, adres email. Po zwalidowaniu wprowadzonych informacji przez system następuje utworzenie nowego konta w systemie z domyślną rolą REGULAR_USER. Administrator systemu aktywuje konto użytkownika i od tego momentu może on korzystać z systemu.
Logowanie użytkownika do systemu - użytkownik wchodzi na stronę logowania, podaje swój login oraz hasło. Po zweryfikowaniu poprawności danych przez system użytkownik przenoszony jest do widoku panelu zbiorczego aplikacji. Interfejs aplikacji jest spersonalizowany pod kątem roli użytkownika, przynależności do zespołów projektowych i przypisanych wymagań.
Modyfikacja profilu użytkownika - zalogowany użytkownik przechodzi do zakładki ustawień, a następnie do panelu profilu użytkownika. Panel ten umożliwia zmianę danych osobowych, adresu email, hasła, itp. Ponadto użytkownik może zarządzać mechanizmem powiadomień o zmianach w przypisanych mu wymaganiach. Po kliknięciu przycisku 'Zapisz' zweryfikowane dane zostają zapisane w systemie
Konta użytkowników z punktu widzenia administratora:
Zarządzanie kontem użytkownika - użytkownik z prawami administratora przechodzi do zakładki ustawień, a następnie do panelu zarządzania kontami użytkowników. Panel ten udostępnia pełną funkcjonalność CRUD dla kont użytkowników. Oprócz podstawowych operacji jak dodawanie, usuwanie, przeglądanie czy edycja, w szczególności administrator może aktywować konto lub je zablokować, zmienić rolę danego użytkownika, zmienić grupę użytkownika lub zresetować jego hasło. Wszystkie modyfikacje są walidowane.
Zarządzanie grupami użytkowników - użytkownik z prawami administratora przechodzi do zakładki ustawień, a następnie do panelu zarządzania grupami użytkowników. Podobnie jak w poprzednim przypadku ma możliwość wykonania wszystkich operacji składających się na przypadek CRUD.
Projekty i zespoły:
Zarządzanie projektami - użytkownik przechodzi do zakładki projektów, a następnie otwiera panel zarządzania portfolio projektów, w którym może dodać, usunąć lub zmodyfikować dowolny projekt. Dodatkowo panel ten umożliwia wybranie aktywnego projektu, czyli tego, z którego przypadki testowe i wymagania mają wyświetlać się w pozostałych widokach.
Zarządzanie zespołem - użytkownik przechodzi do panelu zarządzania zespołem dla aktywnego projektu, w którym ma możliwość przypisania/usunięcia dowolnego użytkownika w systemie do/z projektu. Przypisanie użytkownika do projektu skutkuje tym, że na swoim panelu zbiorczym będzie on widział informacje dotyczące tego projektu, a także tym, że będzie otrzymywał powiadomienia o wszelkich ważnych zmianach w projekcie.
Wymagania i ich zestawy:
Zarządzanie zestawami wymagań - użytkownik przechodzi do zakładki budowania testów, a następnie otwiera panel zarządzania wymaganiami. Panel ten umożliwia zarządzanie zestawami wymagań oraz samymi wymaganiami. Samo zarządzanie zestawami wymagań odbywa się z poziomu menu kontekstowego komponentu-drzewka, reprezentującego hierarchię wymagań i ich zestawów. Użytkownik może dodać zestaw, usunąć go lub zmienić mu nazwę.
Tworzenie/edycja wymagań - użytkownik znajdując się w panelu zarządzania wymaganiami widzi wspomniane drzewko oraz tabelę wyświetlającą wymagania dla aktualnie wybranego zestawu. Drzewko umożliwia kopiowanie wymagań i przeciąganie ich pomiędzy zestawami metodą 'Drag & Drop'. Z poziomu tego widoku użytkownik może utworzyć nowe wymaganie lub przejść do widoku edycji wymagania (po dwukrotnym jego kliknięciu). Obie akcje powodują wyświetlenie formularza umożliwiającego edycję wymagania, czyli m.in.: jego nazwy, opisu, statusu, użytkownika odpowiedzialnego za przetestowanie wymagania.
Usuwanie wymagań - usuwanie wymagań odbywa się z poziomu drzewka (poprzez wybranie opcji usuń z menu kontekstowego) lub z poziomu tabeli wymagań. Pewnym ułatwieniem jest umożliwienie zaznaczenia wielu wymagań i usunięcia ich jednym kliknięciem (multiselect). Każda operacja usunięcia musi zostać potwierdzona.
Przeglądanie i filtrowanie wymagań - specjalne pole w panelu zarządzania wymaganiami umożliwia filtrowanie wyświetlanych wymagań. Użytkownik wybiera z dostępnej listy opcji, te które odpowiadają interesującym go wymaganiom, a system filtruje wyświetlane rekordy zgodnie z wybranymi ograniczeniami.
Przypadki testowe i ich zestawy:
Zarządzanie zestawami przypadków testowych - użytkownik przechodzi do panelu zarządzania przypadkami testowymi w zakładce budowania testów. Zarządzanie zestawami przypadków testowych odbywa się w taki sam sposób jak zarządzanie zestawami wymagań. Krótko mówiąc- nudny CRUD.
Tworzenie/edycja przypadków testowych - przejście do formularza edycji/tworzenia nowego przypadku testowego odbywa się analogicznie jak w przypadku wymagań. Przejście do trybu edycji powoduje zablokowanie przypadku testowego, dzięki czemu inni użytkownicy nie mają możliwości edycji tego przypadku. Po wyświetleniu formularza użytkownik może zmodyfikować takie właściwości przypadku testowego jak: nazwa, priorytet czy prerekwizyty. Oprócz tego może on oczywiście dodawać kroki procedury testowej oraz oczekiwane rezultaty. Zapisanie zmian powoduje ich walidację oraz zapisanie w bazie.
Przypisywanie wymagań do przypadków testowych - znajdując się w widoku edycji przypadku użytkownik korzystając z dwóch list dodaje do przypadku testowego wymagania pokrywane przez dany przypadek. Do wyboru ma wymagania zdefiniowane dla aktywnego projektu.
Usuwanie przypadków testowych - użytkownik przechodzi do panelu zarządzania przypadkami testowymi i po wybraniu przypadku (w drzewku projektu lub w tabeli) naciska przycisk 'Usuń'. Zostaje wyświetlony komunikat z prośbą o potwierdzenie operacji. Pozytywna odpowiedź skutkuje usunięciem wskazanych rekordów z bazy.
Przeglądanie przypadków testowych - przeglądanie przypadków testowych odbywa się w panelu zarządzania przypadkami testowymi. Aby wykonywanie tej czynności było wygodne, przeglądanie odbywa się z wykorzystaniem drzewa reprezentującego hierarchię projektu oraz tabeli wyświetlającej przypadki z danego zestawu przypadków. Tabela ta wyświetla m.in. informacje o autorze każdego przypadku, dacie modyfikacji, stanie (zablokowany/niezablokowany) i ew. użytkowniku, który aktualnie edytuje przypadek. Po kliknięciu przypadku zostaje wyświetlony bardziej szczegółowy widok, który dodatkowo wyświetla informacje o powiązanych wymaganiach.
Raporty, panel zbiorczy, wyszukiwanie:
Przeglądanie raportów dot. postępów projektu - użytkownik otwiera zakładkę panelu zbiorczego, w następstwie zostaje wyświetlony widok zawierający raporty dla aktywnego projektu, tj.: raport w postaci wykresu błędów w testach na przestrzeni czasu, stanu pokrycia wymagań testami, ilości przeprowadzonych testów.
Przeglądanie raportów dot. aktywności użytkowników - w panelu zbiorczym użytkownik otwiera widok raportów na temat aktywności użytkowników w danym projekcie. Widok ten prezentuje ostatnio zmienione lub dodane wymagania i testy, wykryte błędy, komentarze użytkowników, itd.
Przeszukiwanie systemu - użytkownik wpisuje szukaną frazę w pole tekstowe w głównym menu aplikacji i naciska przycisk 'Szukaj'. W odpowiedzi system wyświetla listę wymagań i przypadków testowych, których opisy zawierają daną frazę.
Testowanie:
Wykonywanie testów - użytkownik otwiera zakładkę wykonywania testów. System wyświetla widok podobny jak w przypadku przeglądania przypadków testowych, z tą różnicą, że zamiast edycji umożliwia przejście do trybu wykonywania testu. Użytkownik wybiera z listy jeden z przypadków testowych i przechodzi do trybu testowania. Nowy widok zawiera listę kroków danego testu wraz z oczekiwanymi rezultatami, a także komponenty umożliwiające zapisanie wyniku każdego z kroków, dodawanie komentarzy czy raportowanie błędów w systemie Jira. Użytkownik wykonuje kolejne kroki testu, przy każdym z nich zaznaczając czy wykonał się poprawnie. Pomyślne wykonanie wszystkich kroków sprawia, że status testu zmienia się na DONE, w przeciwnym wypadku zostaje ustawiony status FAILED. Należy zaznaczyć, że wystąpienie błędu wymusza na użytkowniku dodanie komentarza, który dokładnie go opisuje. Dodatkowo pojawia się komunikat, który mówi, że zgłoszenie błędu systemie Jira jest zalecane, aczkolwiek niekonieczne.
Identyfikacja funkcji
Podstawowe funkcje realizowane przez system na bazie danych będą skupiały się wokół przechowywania i udostępniania informacji na temat:
Analiza hierarchii funkcji projektowanej aplikacji
Budowa i analiza diagramu przepływu danych
Diagram kontekstowy
Diagram wstępny
1. Analiza projektu
2. Zarządzanie projektami
3. Wykonywanie testów
4. Budowanie testów
5. Zarządzanie kontem
6. Zarządzanie użytkownikami
Wybór encji (obiektów) i ich atrybutów
W systemie zidentyfikowano następujące encje:
Atrybuty tych encji oraz relacje pomiędzy encjami zaprezentowano na poniższym diagramie ERD.
Projektowanie powiązań (relacji) pomiędzy encjami
Projekt diagramów STD
Projektowanie tabel, kluczy, kluczy obcych, powiązań między tabelami, indeksów, etc. w oparciu o zdefiniowany diagram ERD
 Projekt SQL:
Projekt SQL:
Schemat bazy danych
Należy w tym miejscu dodać, że dla każdego klucza głównego w bazie danych automatycznie tworzony jest indeks typu B-tree, co jest domyślnym zachowaniem systemu PostgreSQL.
Słowniki danych
Tabela REQUIREMENT_SETS:
RQS_ID - liczba całkowita, wymagane, automatycznie generowany identyfikator
RQS_NAME ciąg znaków, długość < 50, wymagane, nazwa zestawu
RQS_PROJECT - liczba całkowita, wymagane, projekt zawierający
Tabela PROJECTS:
PR_ID - liczba całkowita, wymagane, automatycznie generowany identyfikator
PR_NAME - ciąg znaków, długość < 20, wymagane, nazwa projektu
Tabela GROUPS:
GR_ID - liczba całkowita, wymagane, automatycznie generowany identyfikator
GR_NAME - ciąg znaków, długość < 50, wymagane, nazwa grupy
Tabela STEPS:
ST_ID - liczba całkowita, wymagane, automatycznie generowany identyfikator
ST_NR - liczba całkowita, wymagane, numer kroku
ST_ACTION - tekst, opis kroku
ST_RESULT - tekst, opis otrzymanego rezultatu
ST_TESTCASE - liczba całkowita, wymagane, przypadek testowy kroku
ST_EXPECTED_RESULT - tekst, oczekiwany wynik testu
ST_JIRA_ISSUE - tekst,
URL do issue w systemie Jira
Tabela REQUIREMENTS:
RQ_ID - liczba całkowita, wymagane, automatycznie generowany identyfikator
RQ_STATUS - ciąg znaków, długość < 15, wymagane, status wymagania [ACCEPTED|REJECTED|NEW]
RQ_CASES_NR - liczba całkowita, wymagane, liczba pokrywających przypadków testowych
RQ_ASSIGNEE - liczba całkowita, wymagane, osoba przypisana do wymagania
RQ_CREATED - timestamp, wymagane, data utworzenia
RQ_REQUIREMENT_SET - liczba całkowita, wymagane, zawierający zestaw
RQ_CONTENT - tekst, opis wymagania
RQ_NAME - ciąg znaków, długość < 50, wymagane, nazwa
RQ_AUTHOR - liczba całkowita, wymagane, autor
RQ_UPDATED - timestamp, data modyfikacji
Tabela TESTCASES:
TC_ID - liczba całkowita, wymagane, automatycznie generowany identyfikator
TC_BLOCKED - boolean, wymagane, stan [ZABLOKOWANY|DOSTĘPNY]
TC_UPDATED - timestamp, wymagane, data modyfikacji
TC_TESTCASE_SET - liczba całkowita, wymagane, zestaw przypadków
TC_BLOCKED_BY - liczba całkowita, użytkownik edytujący
TC_NAME - ciąg znaków, długość < 50, wymagane, nazwa
TC_PRIORITY - ciąg znaków, długość < 15, wymagane, priorytet [HIGH|MEDIUM|LOW]
TC_PREREQUISITES - tekst, prerekwizyty
TC_AUTHOR - liczba całkowita, wymagane, autor
Tabela USERS:
USR_ID - liczba całkowita, wymagane, automatycznie generowany identyfikator
USR_NAME - ciąg znaków, długość < 20, wymagane, imię
USR_SURNAME - ciąg znaków, długość < 30, wymagane, nazwisko
USR_LOGIN - ciąg znaków, długość < 30, wymagane, login
USR_EMAIL - ciąg znaków, długość < 30, wymagane, adres email
USR_ROLE - ciąg znaków, długość < 20, wymagane, rola [REGULAR_USER|ADMIN]
USR_GROUP - liczba całkowita, grupa
USR_ACTIVE - boolean wymagane, stan [ACTIVE|INACTIVE]
USR_PASSWORD - tekst wymagane, hash hasła
Tabela TESTCASE_SETS:
TCS_ID - liczba całkowita, wymagane, automatycznie generowany identyfikator
TCS_NAME - ciąg znaków, długość < 50, wymagane, nazwa
TCS_PROJECT - liczba całkowita, projekt zawierający
Analiza zależności funkcyjnych i normalizacja tabel
Pierwsza postać normalna (1NF)
Wszystkie atrybuty encji w przedstawionym modelu są atomiczne, a więc baza danych spełnia warunek pierwszej postaci normalnej.
Druga postać normalna (2NF)
Aby spełniona była druga postać normalna wszystkie atrybuty niekluczowe encji muszą zależeć od całego klucza głównego tej encji. W przedstawionym schemacie wszystkie tabele z wyjątkiem PROJECT_USERS i TESTCASE_REQUIREMENTS posiadają klucz główny prosty, a więc warunek ten jest spełniony. Z kolei tabele PROJECT_USERS oraz TESTCASE_REQUIREMENTS są typowymi tabelami asocjacyjnymi i nie posiadają atrybutów niekluczowych.
Trzecia postać normalna (3NF)
Baza danych spełnia trzecią postać normalną. W żadnej z encji opracowanego modelu nie występują relacje tranzytywne, wszystkie atrybuty zależą bezpośrednio od klucza głównego.
Projektowanie operacji na danych
W projekcie zostanie wykorzystane rozwiązanie ORM Hibernate, które przejmuje od nas odpowiedzialność za operowanie na bazie danych. Poniżej przedstawiona została przykładowa implementacja klasy-encji, reprezentującej przypadek testowy:
package pl.edu.agh.testo.data;
@Entity
@SequenceGenerator(initialValue = 1, name = "idgen", sequenceName = "testcase_seq")
public class TestCase implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO, generator = "idgen")
private Long testCaseId;
private String name;
private boolean blocked;
private Date created;
private Date updated;
private TestCasePriority priority;
private String prerequisites;
@ManyToOne
private AppUser author;
@ManyToOne
private TestCaseSet testCaseSet;
@ManyToOne
private AppUser blockedBy;
@ManyToMany
@JoinTable(
name="testcase_requirement",
joinColumns=@JoinColumn(name="testcase_id"),
inverseJoinColumns=@JoinColumn(name="requirement_id")
)
private Set<Requirement> requirements;
@OneToMany(mappedBy = "testCase", cascade = CascadeType.ALL)
@Cascade(org.hibernate.annotations.CascadeType.DELETE_ORPHAN)
@JoinColumn(name = "testCaseId")
private Set<Step> steps;
public TestCase() {
}
public Long getTestCaseId() {
return testCaseId;
}
//getters and setters...
}
Reprezentatywne przykłady zapytań SQL generowanych przez Hibernate:
a) pobieranie listy projektów dla panelu zarządzania projektami:
select this_.projectId as projectId0_0_, this_.name as name0_0_ from Project this_ order by this_.projectId asc limit ?
b) aktualizacja nazwy projektu
update Project set name=? where projectId=?
c) tworzenie nowego projektu
insert into Project (name, projectId) values (?, ?)
d) pobranie listy wymagań dla panelu zarządzania wymaganiami
select this_.requirementId as requirem1_4_5_, this_.assignee_appUserId as assignee8_4_5_, this_.author_appUserId as author9_4_5_, this_.content as content4_5_,
this_.created as created4_5_, this_.name as name4_5_, this_.numberOfCases as numberOf5_4_5_, this_.requirementSetId as require10_4_5_, this_.requirementStatus
as requirem6_4_5_, this_.updated as updated4_5_, appuser3_.appUserId as appUserId6_0_, appuser3_.active as active6_0_, appuser3_.email as email6_0_,
appuser3_.group_userGroupId as group8_6_0_, appuser3_.login as login6_0_, appuser3_.name as name6_0_, appuser3_.password as password6_0_, appuser3_.role as
role6_0_, usergroup4_.userGroupId as userGrou1_5_1_, usergroup4_.name as name5_1_, appuser5_.appUserId as appUserId6_2_, appuser5_.active as active6_2_,
appuser5_.email as email6_2_, appuser5_.group_userGroupId as group8_6_2_, appuser5_.login as login6_2_, appuser5_.name as name6_2_, appuser5_.password as
password6_2_, appuser5_.role as role6_2_, rs1_.requirementSetId as requirem1_2_3_, rs1_.name as name2_3_, rs1_.projectId as projectId2_3_, project7_.projectId
as projectId0_4_, project7_.name as name0_4_
from Requirement this_ left outer join AppUser appuser3_ on this_.assignee_appUserId=appuser3_.appUserId
left outer join UserGroup usergroup4_ on appuser3_.group_userGroupId=usergroup4_.userGroupId
left outer join AppUser appuser5_ on this_.author_appUserId=appuser5_.appUserId
inner join RequirementSet rs1_ on this_.requirementSetId=rs1_.requirementSetId
left outer join Project project7_ on rs1_.projectId=project7_.projectId where rs1_.projectId=?
order by this_.requirementId asc limit ?
e) modyfikacja wymagania
update Requirement set assignee_appUserId=?, author_appUserId=?, content=?, created=?, name=?, numberOfCases=?, requirementSetId=?, requirementStatus=?,
updated=? where requirementId=?
f) usunięcie wymagania
delete from testcase_requirement where requirementId=?
delete from Requirement where requirementId=?
Jak widać zapytania generowane przez Hibernate nie zawsze są optymalne. Przykładowo- pobranie obiektu klasy Requirement pociąga za sobą pobranie całej struktury obiektów powiązanych, a co za tym idzie wykonanie pięciu złączeń, pomimo, że nie potrzebujemy wszystkich zawartych w nich danych. Jest to bolączka wszystkich rozwiązań ORM. Pewną rekompensatą jest zastosowanie cache'u. Inną metodą łagodzenia problemu są różne fetching strategies, które definiuje Hibernate (np. domyślną strategią dla kolekcji jest lazy fetching dzięki czemu kolekcje ładowane są dopiero wówczas kiedy są potrzebne).
Implementacja bazy danych
Wykorzystanie w projekcie biblioteki Hibernate sprawiło, że implementacja bazy danych sprowadziła się do skonfigurowania samego Hibernate'a oraz utworzenia modelu danych opisanego za pomocą adnotacji zdefiniowanych w standardzie JPA. Zastosowanie rozwiązania ORM pozwoliło na znaczne przyspieszenie prac i uwolniło nas od konieczności utrzymywania schematu bazy zgodnego z aktualnym modelem danych aplikacji.
Poniższy listing przedstawia kod klasy HibernateUtil odpowiedzialnej za konfigurację połączenia z bazą oraz zarządzanie instancją klasy SessionFactory:
public class HibernateUtil {
private static final SessionFactory sessionFactory;
static {
try {
AnnotationConfiguration cnf = new AnnotationConfiguration();
cnf.setProperty(Environment.DRIVER, "org.postgresql.Driver");
cnf.setProperty(Environment.URL, "jdbc:postgresql://localhost:5432/tessto");
cnf.setProperty(Environment.USER, "user");
cnf.setProperty(Environment.PASS, "password");
cnf.setProperty(Environment.DIALECT, PostgreSQLDialect.class.getName());
cnf.setProperty(Environment.SHOW_SQL, "true");
cnf.setProperty(Environment.HBM2DDL_AUTO, "create-drop");
cnf.setProperty(Environment.CURRENT_SESSION_CONTEXT_CLASS, "thread");
cnf.addAnnotatedClass(Project.class);
cnf.addAnnotatedClass(TestCaseSet.class);
cnf.addAnnotatedClass(RequirementSet.class);
cnf.addAnnotatedClass(TestCase.class);
cnf.addAnnotatedClass(Requirement.class);
cnf.addAnnotatedClass(UserGroup.class);
cnf.addAnnotatedClass(AppUser.class);
cnf.addAnnotatedClass(Step.class);
sessionFactory = cnf.buildSessionFactory();
}
catch (Throwable ex) {
System.err.println("Initial SessionFactory creation failed." + ex);
throw new ExceptionInInitializerError(ex);
}
}
public static SessionFactory getSessionFactory() {
return sessionFactory;
}
}
Opcja cnf.setProperty(Environment.HBM2DDL_AUTO, „create-drop”) powoduje automatyczne wygenerowanie poleceń SQL budujących strukturę bazy i wykonanie ich na bazie.
POJO reprezentujące wymaganie wraz z adnotacjami:
@Entity
@SequenceGenerator(initialValue = 1, name = "idgen", sequenceName = "requirement_seq")
public class Requirement implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO, generator = "idgen")
private Long requirementId;
private String name;
private String content;
private RequirementStatus requirementStatus;
private int numberOfCases;
private Date created;
private Date updated;
@ManyToOne
private AppUser author;
@ManyToOne
private AppUser assignee;
@ManyToOne
@JoinColumn(name = "requirementSetId")
private RequirementSet requirementSet;
@ManyToMany
@JoinTable(
name="testcase_requirement",
joinColumns=@JoinColumn(name="requirementId"),
inverseJoinColumns=@JoinColumn(name="testCaseId")
)
private Set<TestCase> testCases;
// getters and setters...
}
Jak widać Hibernate oferuje szereg ułatwień jak np. automatyczną obsługę relacji many-to-many. Wykorzystując adnotację @ManyToMany nie musimy sami tworzyć tabel asocjacyjnych- robi to za nas Hibernate.
Zdefiniowanie interfejsów do prezentacji, edycji i obsługi danych
Zarządzanie projektami
Panel ten odpowiada stanowi 'Zarządzanie projektami' na diagramie STD i przypadkowi użycia 'Projekty i zespoły: Zarządzanie projektami'.

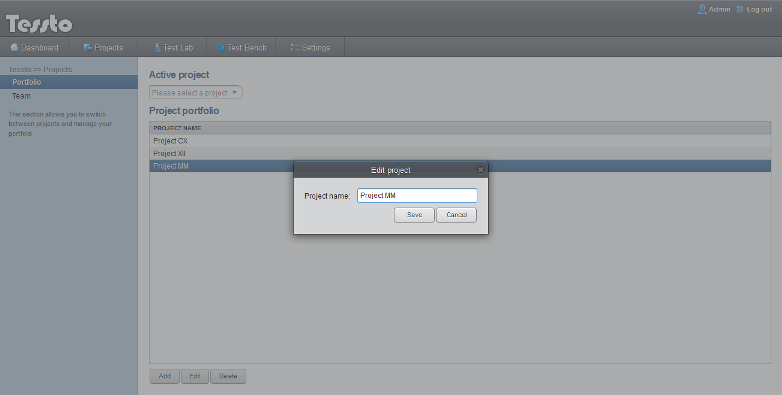
Edycja projektu
Panel ten odpowiada stanowi 'Edycja projektu' na diagramie STD i przypadkowi użycia 'Projekty i zespoły: Zarządzanie projektami'.
Przeglądanie przypadków testowych
Panel ten odpowiada stanowi 'Budowanie testów - listy wymagań i przypadków testowych (Test Workbench)' na diagramie STD i przypadkom użycia 'Zarządzanie zestawami przypadków testowych', 'Tworzenie/edycja przypadków testowych', 'Usuwanie przypadków testowych' oraz 'Przeglądanie przypadków testowych' z grupy 'Przypadki testowe i ich zestawy'.

Podgląd przypadku testowego
Panel ten odpowiada stanowi 'Budowanie testów - listy wymagań i przypadków testowych (Test Workbench - podgląd przypadku)' na diagramie STD i przypadkom użycia 'Zarządzanie zestawami przypadków testowych' oraz 'Przeglądanie przypadków testowych' z grupy 'Przypadki testowe i ich zestawy'.

Edycja przypadku testowego
Panel ten odpowiada stanowi 'Formularz tworzenia/edycji przypadków testowych' na diagramie STD i i przypadkom użycia 'Zarządzanie zestawami przypadków testowych', 'Tworzenie/edycja przypadków testowych' oraz 'Przypisywanie wymagań do przypadków testowych' z grupy 'Przypadki testowe i ich zestawy'.

Przeglądanie wymagań
Panel ten odpowiada stanowi 'Budowanie testów - listy wymagań i przypadków testowych (Test Workbench)' na diagramie STD i przypadkom użycia 'Zarządzanie zestawami wymagań', 'Usuwanie wymagań' oraz 'Przeglądanie i filtrowanie wymagań' z grupy 'Wymagania i ich zestawy'.

Podgląd wymagania
Panel ten odpowiada stanowi 'Budowanie testów - listy wymagań i przypadków testowych (Test Workbench - podgląd wymagania)' na diagramie STD i przypadkom użycia 'Zarządzanie zestawami wymagań' oraz 'Przeglądanie i filtrowanie wymagań' z grupy 'Wymagania i ich zestawy'.

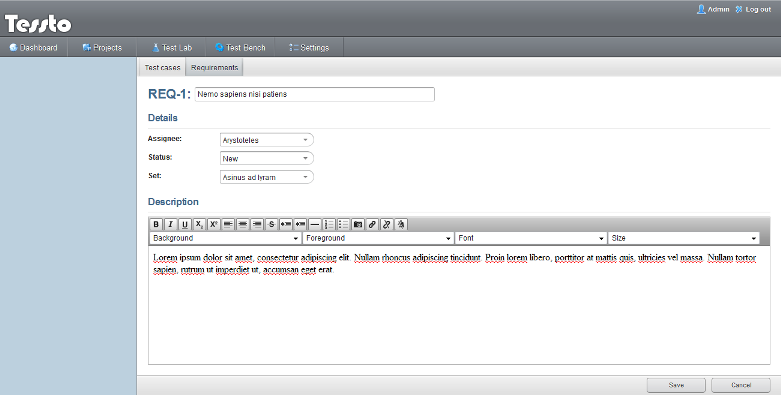
Edycja wymagania
Panel ten odpowiada stanowi 'Formularz tworzenia/edycji wymagań' na diagramie STD i przypadkom użycia 'Zarządzanie zestawami wymagań' oraz 'Tworzenie/edycja wymagań' z grupy 'Wymagania i ich zestawy'.
Uruchamianie i testowanie aplikacji/ Wdrażanie systemu do użytkowania
Aplikacja została stworzona z wykorzystaniem frameworka Vaadin bazującego na technologii GWT. Paczka instalacyjna ma więc postać archiwum WAR obsługiwanego przez dowolny kontener serwletów (Tomcat, Jetty, itp.). Do zainstalowania aplikacji wymagane są następujące elementy:
W razie konieczności skalowania aplikacji można wykorzystać przykładowo serwer HTTP Apache z modułem mod_jk, działający w charakterze proxy/load balancera dla kilku instancji kontenerów.
Wdrożona instancja aplikacji dostępna jest pod adresem http://lukasz.sanek.org.pl/tessto
Zapewnienie dokumentacji technicznej i użytkowej
Dokumentacja powinna zawierać:
opis interfejsu aplikacji z punktu widzenia zwykłego użytkownika
opis zarządzania projektami z punktu widzenia użytkownika o uprawnieniach administratora
instrukcję instalacji/aktualizacji oraz konfiguracji aplikacji dla administratora systemu
Rozwijanie i modyfikowanie aplikacji
W chwili obecnej aplikacja pozwala na wykonywanie podstawowych czynności związanych z zarządzaniem projektami, wymaganiami i przypadkami testowymi. Na dalszych etapach rozwoju należałoby rozważyć rozbudowanie jej o takie funkcjonalności jak:
Wersjonowanie przypadków testowych i wymagań
Integracja z JIRĄ i Hudsonem
Rozbudowane raporty o stanie testów
Automatyczne estymacje czasu wykonywania poszczególnych przypadków testowych bazujące na danych historycznych
Wyszukiwanie pełnotekstowe w opisach przypadków i wymagań
Dołączanie screenshotów do opisów błędów (wbudowane narzędzie do wykonywania zrzutów interesujących obszarów ekranu)
Opracowanie doświadczeń wynikających z realizacji projektu
Jak już zostało wspomniane aplikacja została stworzona z wykorzystaniem frameworka Vaadin, który powstał z myślą o budowaniu aplikacji RIA w Javie. O wyborze technologii zadecydowały takie czynniki jak: obszerna dokumentacja, łatwość wdrożenia się w technologię (dla osób, które korzystały już ze Swinga/AWT lub SWT), aktywna społeczność i możliwość tworzenia aplikacji AJAX bez konieczności poznawania technologii JavaScript. Decyzja okazała się trafna- w krótkim czasie udało się zapoznać z technologią i zrealizować projekt bez większych problemów, w głównej mierze dzięki dużej liczbie dostępnych przykładów i wsparciu ze strony społeczności. Obszerne portfolio gotowych komponentów, a także łatwość wprowadzania własnych modyfikacji przyczyniły się do stworzenia produktu o wysokim poziomie użyteczności.
Należy także wspomnieć o bibliotece Hibernate, której wykorzystanie pozwoliło na znaczne uproszczenie pracy z warstwą modelu i jego persystencją w bazie danych. Dodatkowy narzut czasowy związany z koniecznością poznania kolejnej technologii w ostatecznym rozrachunku okazał się trafioną inwestycją.
Wykaz literatury
Załączniki



















