Probabilistic Programming — Diagnosis and Prediction
This class will cover use cases of the Bayesian methods in the medical domain. First part of the class is based on article: “Local computations with probabilities on graphical structures and their application to expert systems” by Lauritzen, Steffen L. and David J. Spiegelhalter. Second part is inspired by “An intercausal cancellation model for bayesian-network engineering. International Journal of Approximate Reasoning” by S.P. Woudenberg, L. C. van der Gaag, and C. M. Rademaker.
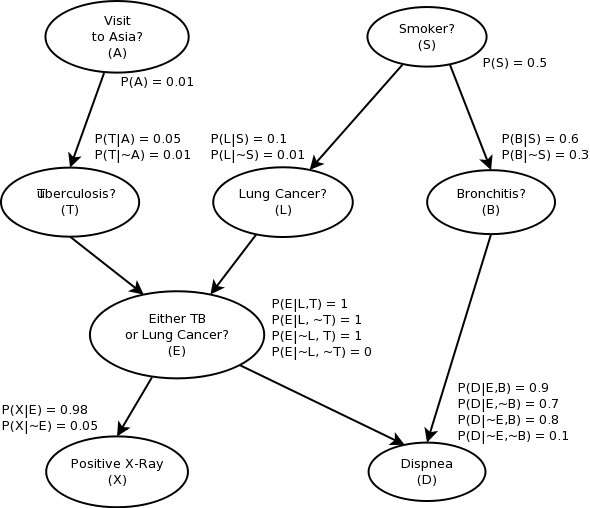
Medical Diagnosis
In this section we will follow a simplified use case of the medical diagnosis, as defined in the following quote from the article.

Structure
First task of the “knowledge engineer” is to find a structure of Bayesian network which fits the story. There exist automatic tools to learn the structure from examples, but in this case the structure should be clear enough to create the network by hand.
Assignments
Draw (on paper?) a Bayesian network describing the story from the previous section.
Write the corresponding Problog program:
Hints:
logical or in Problog:
a_or_b :- a.
a_or_b :- b.
you can have lung cancer even if you are not a smoker, so don't forget to mention this fact in the model. There are two ways to do that:
classical (Bayesian network):
0.1::cancer :- smoker.
0.01::cancer :- \+ smoker.
pros: it's a classical approach with clean Bayesian semantics
cons: including new variables into the model can grow number of rules exponentially; also it may be required to modify already existing rules
Problog 'additive way':
0.1::cancer :- smoker.
0.01::cancer.
pros: including new variable doesn't involve change of the old rules; you just add new rule per variable
cons: the probabilities will be different than in the Bayesian network; so you can't just copy the Bayesian network structure ;)
x-ray can be positive even if you're healthy
Probabilities
The problem with Bayesian model you've just created is that it doesn't provide with any useful info. Mostly because of the arbitrary prior probabilities, you've used. Reality is rather harsh, often you don't have access to any realistic priors (one of the arguments of critics of Bayesian methods). In this section we will try to make up for that and find make the network useful.
Learning
The simplest way to have realistic priors is to not have any priors at all :) In other words — we assume, we know nothing about probabilities. In Problog you can state this fact by using t(_) predicate, e.g.
t(_)::smoker.
Says you do not know nothing about probability of patient being smoker.
Now when we have admitted our lack of knowledge, we can start learning! In Problog learning can be achieved either by command line tool:
problog lfi
or in on-line editor by simply choosing Learning from the list.
In both cases you have to provide some learning examples, that consists simply of evidences separated by dotted line, e.g. two different patients can be described as:
evidence(smoker).
evidence(\+visitedAsia).
evidence(\+tubercolosis).
evidence(\+lung_cancer).
evidence(\+dyspnea).
evidence(\+xray_positive).
----------------
evidence(\+xray_positive).
evidence(tubercolosis).
evidence(visitedAsia).
evidence(\+lung_cancer).
evidence(dyspnea).
evidence(\+smoker).
The learning should result in new model with new probabilities.
If you receive an “Inconsistent Evidence” error, it means that your model is not compatible. Sometimes the simplest way to solve this problem is to include leak probabilities in the model. Leak probabilities are probabilities stating that some random variable can be assigned to a value without any particular reason, e.g. here we state that variable var can't be true because of an external reason.
t(_)::var :- reason1.
t(_)::var :- reason2.
0.0::var. % leak probability
Command line tool can do it automatically (check prolog lfi –help).
Assignments:
replace all probabilities in your model with t(_)
put some random learning data in the on-line IDE and check results of learning
can you think of possible difficulties of this approach?
-
try to use it in on-line IDE
try to use it offline (cmdline)
you may have to ask the teacher to install the problog for you
you may have to limit number of iterations learning takes
you may have to provide to a file for the output model
-
what are the learned probabilites?
what is the probability of a smoker with positive x-ray to have a lung cancer?
Learning + Priors
The previous section was neat, but reality is really harsh and it's realy difficult to get good learning data of 10 000 patients. Therefore we need to go for compromise and combine priors with learning. To do that in Problog it's enough to put a probability in the t/1 predicate, e.g. to tell that in the society 50% people smoke, but you are not sure of this, you should write:
t(0.50)::smoker.
Now, let's say we have found some wise books that say:
30% of the population smokes
0.01% of the population has been in Asia
dyspnea is mostly caused by asthma and causes other than TB, lung cancer, or bronchitis
smoking has greater impact on lung cancer than on bronchitis
Assignments
introduce the knowledge from the wise books in your model
-
Sampling
Now, if you want to generate learning data yourself, you can do it via so called sampling of the model.
To do that you have to add queries for every variable you want to sample and then:
Assignments
generate 100 random patients and feed them to the model
it may be easier using the command line tool ;)
Predicting Treatment's Effects
Every doctor has to prescribe some kind of treatment. Our task is to provide him with tools that could help predict the treatments effects. Here is a new story:
Doctor has to treat patients with primary type-1 osteoporosis. Two common treatments for osteoporosis are calcium supplementation and medication with bisphosphonates. The bisphosphonates are much more effective than calcium, but the concurrent intake of both medications will fully cancel out the effect of the bisphosphonates and the effect of the calcium supplementation is cancelled out partially.
In other words:
There is a special syntax in Problog to say that a variable has a negative impact on (inhibits) another variable. You just have to put a negation before the rule head, e.g. to say that variable a can be true when variable b is true:
\+a :- b.
, and to write that there is 50% chance that a won't be true if b is true:
0.50::\+a :- b.
Assignments
write a corresponding Problog program:
what is the chance of successful treatment when we use both calcium and bisphosphonates?
{kind=link}