Drzewo Gry - Monte Carlo Tree Search
Poniższe laboratorium jest kontynuacją laboratorium o klasycznych algorytmach działających na drzewie gry i zakłada zrozumienie przedstawionych na nim treści. W ramach laboratorium zaprezentowany będzie sławny algorytm Monte Carlo Tree Search (MCTS). O ile algorytm MiniMax z cięciami Alpha-Beta reprezentuje podejście branch and bound do wyczerpującego przeszukiwania drzewa gry, o tyle w przypadku gier o dużym współczynniku rozgałęzienia jest to niemożliwe, np. w przypadku sławnej gry Go.
Algorytm MCTS należy do dużej rodziny algorytmów próbkujących, często używanych w przypadku rozumowań probabilistycznych.
Powiązane materiały:
Algorytm Monte Carlo
 Nazwa Monte Carlo pochodzi od sławnych kasyn, w których znaleźć można automaty typu „jednoręki bandyta”. W przypadku drzewa gier mamy w danej turze to wyboru kilka ruchów, które mogą (lecz nie muszą) zapewnić nam zwycięstwa. Każdy możliwy ruch możemy potraktować jako automat do gry z nieznanym prawdopodobieństwem wygranej, a wybór ruchu to po prostu wybór automatu, na którym przepuścimy kolejny żeton. Na początku nie wiemy, który automat daje większą szansę na zwycięstwo - dlatego też wybieramy dowolny (losowy) z nich. Następnie zapisujemy wynik z gry i ponawiamy grę losując automat. Robimy to tak długo jak tylko jesteśmy w stanie - cały czas zapisując wyniki gier. Następnie wybieramy ten automat, który dał nam najwięcej zwycięstw. W przełożeniu na język drzewa gry - wykonujemy możliwie dużo losowych symulacji gier i wybieramy ten ruch, który średnio najczęściej doprowadzał do zwycięstwa.
Nazwa Monte Carlo pochodzi od sławnych kasyn, w których znaleźć można automaty typu „jednoręki bandyta”. W przypadku drzewa gier mamy w danej turze to wyboru kilka ruchów, które mogą (lecz nie muszą) zapewnić nam zwycięstwa. Każdy możliwy ruch możemy potraktować jako automat do gry z nieznanym prawdopodobieństwem wygranej, a wybór ruchu to po prostu wybór automatu, na którym przepuścimy kolejny żeton. Na początku nie wiemy, który automat daje większą szansę na zwycięstwo - dlatego też wybieramy dowolny (losowy) z nich. Następnie zapisujemy wynik z gry i ponawiamy grę losując automat. Robimy to tak długo jak tylko jesteśmy w stanie - cały czas zapisując wyniki gier. Następnie wybieramy ten automat, który dał nam najwięcej zwycięstw. W przełożeniu na język drzewa gry - wykonujemy możliwie dużo losowych symulacji gier i wybieramy ten ruch, który średnio najczęściej doprowadzał do zwycięstwa.
dopóki starczy czasu:
pierwszy_ruch = wybierz_losowy_ruch()
wynik = losowa_symulacja(pierwszy_ruch)
zapisz_wynik(pierwszy_ruch)
policz_średnie_wyniki_dla_każdego_ruchu()
wybierz_ruch_o_największym_średnim_wyniku()
Ćwiczenia
proszę przyjrzeć się przykładowej implementacji algorytmu Monte Carlo z pliku SampleMonteCarloGamer.java
proszę przeprowadzić pojedynek między algorytmem Alpha-Beta (lub przynajmniej zwykłym MiniMax) i algorytmem Monte Carlo:
na małej grze, np. kółko i krzyżyk
na dużej grze, np. warcabach normalnych rozmiarów
w obu przypadkach algorytmy powinny dbać o to, żeby nie było timeoutów.
Monte Carlo Tree Search
Bardziej ambitnym rozszerzeniem algorytmu Monte Carlo jest inteligentne próbkowanie automatów do gry. Zamiast losowo wybierać automat do gry, faworyzujemy automaty, które sprawowały się najlepiej, tj. z początku gramy zupełnie losowo, z czasem coraz bardziej przekonując się do wybierania automatów, z którymi dotychczas najczęściej wygrywaliśmy. Matematycznie, można to wyrazić za pomocą formuły:

gdzie:

to dotychczasowy średni wynik

-tej maszyny

to parametr odpowiadający za to, jaką część czau algorytm poświęci na eksplorację nieznanych ruchów:
domyślna wartość wynikająca z teorii wynosi


to liczba rozegranych gier

to liczba gier rozegranych na
-tej maszynie
Formuła UCT z jednej strony faworyzuje ruchy, które mają duży średni wynik; z drugiej strony druga część formuły zwraca większe wartości dla ruchów mniej sprawdzonych.
W przypadku przeszukiwania drzewa gry podobny problem należy rozwiązać w każdym przeszukiwanym węźle. Dla wszystkich możliwych do wykonania ruchów prowadzimy statystykę liczby zwycięstw i wszystkich symulacji danego ruchu. Z początku ruchy są losowe, później jednak zaczynają faworyzować tę część drzewa gry, która zawiera obiecujące ruchy.
Algorytm można podzielić na cztery fazy:
wybór: jeżeli wszystkie możliwe ruchy z przeszukiwanego węzła mają policzone statystyki (każdy już kiedyś był zagrany) używamy formuły UCT, aby wybrać ruch. Jeśli nie, przechodzimy do fazy rozrostu.
 UWAGA
UWAGA podobnie jak w algorytmie MiniMax zakładamy, że na przemian wykonywane są ruchy nasze i wroga. Jeżeli wróg wykonuje ruch, stara się maksymalizować swoje wyniki (lub minimalizować nasze, co jest tożsame w przypadku gier o sumie zerowej). Zatem, albo modyfikujemy formułę UCT, np. :

, albo odpowiednio zapisujemy wyniki.
rozrost: jeżeli żaden ruch z danego węzła nie był nigdy grany, wybieramy losowy jeszcze niegrany ruch.
symulacja: z węzła wybranego w fazie rozrostu, przeprowadzamy losową symulację Monte Carlo
propagacja wyników wstecz: po wygranej lub przegranej, odpowiednio aktualizujemy statystyki odpowiednich ruchów (nie obejmuje to ruchów wykonanych w ramach symulacji).
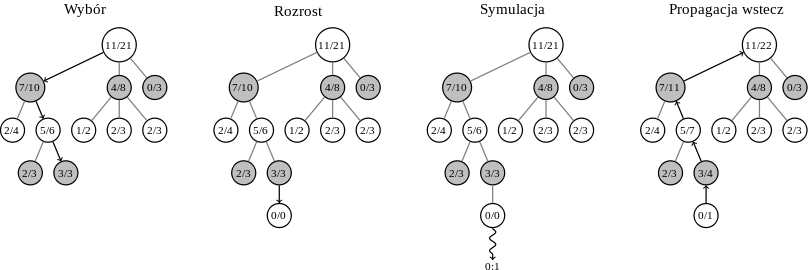
Szare kółka (ruchy wroga) minimalizują liczbę naszych zwycięstw.
Powyższe fazy powtarzają się tak długo, jak jest to możliwe. Na końcu wybieramy ten ruch, który został zasymulowany największą ilość razy. Jego jakość jest zapewniona poprzez fakt, że algorytm z natury skupia przeszukiwanie wokół najlepszych możliwości.
Ćwiczenia
Bazując na graczu SampleMonteCarloGamer.java, proszę zaimplementować gracza SampleMCTSGamer.java
należy zauważyć, że algorytm MCTS zakłada, że nagroda za zwycięstwo wynosi 1, a nie 100. Podobnie remis powinien być traktowany jako 0,5.
Proszę przeprowadzić serię pojedynków SampleMCTSGamer.java vs SampleMonteCarloGamer.java w warcaby normalnych rozmiarów lub inną grę o dużej przestrzeni przeszukiwania, czy widać różnicę między wynikami tych botów?
Proszę powtórzyć serię pojedynków, zmieniając stałą eksploracji
na wartości: 0, 1, 2, 5, 42. Która z nich daje najlepsze wyniki?
Proszę zmodyfikować algorytm MCTS tak, żeby przed przejściem do wyboru z użyciem UCT, najpierw zagrał pewną liczbę (np. tyle, ile zdążyć przez 1/5 dozwolonego czasu) czystych symulacji Monte Carlo. Czy poprawia to jakość wyników?

