LAB: Uczenie nadzorowane
1 Do przygotowania
2 Wprowadzenie [10 minut]
Czy znasz odpowiedzi na poniższe pytania?
Czym różnią się uczenie nadzorowane, nienadzorowane i reinforcement learning?
Czym różni się regresja od klasyfikacji?
Co to jest regresja liniowa?
Co to jest drzewo decyzyjne?
Co to jest sieć neuronowa?
Na czym polega problem nadmiernego dopasowania (ang. overfitting)?
Jak sobie radzić z tym problemem w przypadku regresji liniowej?
Jak sobie radzić z tym problemem w przypadku drzewa decyzyjnego?
Jak sobie radzić z tym problemem w przypadku sieci neuronowych?
Na czym polega walidacja krzyżowa (ang. cross validation)?

(źródło)
Weka
Weka, to narzędzie opensource do data miningu.
Uruchom je wykonując w konsoli polecenie:
$ weka
Jeśli program nie jest zainstalowany, ściągnij go ze strony Weka i uruchom:
$ java -jar weka.jar
Jeżeli jesteś w laboratorium C2 208/216 uruchom wekę wpisując w terminalu:
$ /usr/local/java-7-oracle/jre1.7.0_79/bin/java -jar /usr/share/java/weka.jar
-
Otwórz w swoim ulubionym edytorze pliki o nazwach swimming.arff oraz cpu.arff i poznaj strukturę plików uczących dla weki z danymi symbolicznymi.
Uruchom Wekę i kliknij w przycisk Explorer
Otwórz w Wece plik
swimming.arff i przeanalizuj pierwszą zakładkę
GUI, a następnie odpowiedz na pytania poniżej:
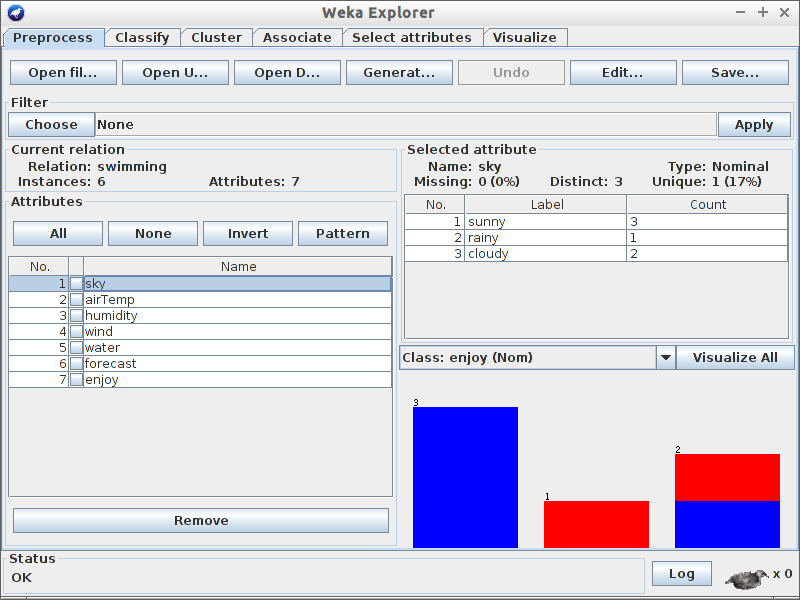
Pytania
Jaki jest rozmiar zbioru uczącego?
Ile atrybutów występuje w zbiorze uczącym?
Ile jest instancji jest pozytywnych (Enjoy=yes) a ile negatywnych?
Który z atrybutów najlepiej rozdziela dane? ;)
Ile elementów ze zbioru danych ma atrybut wilgotność (humidity) ustawioną jako high?
3 Regresja liniowa [15 minut]
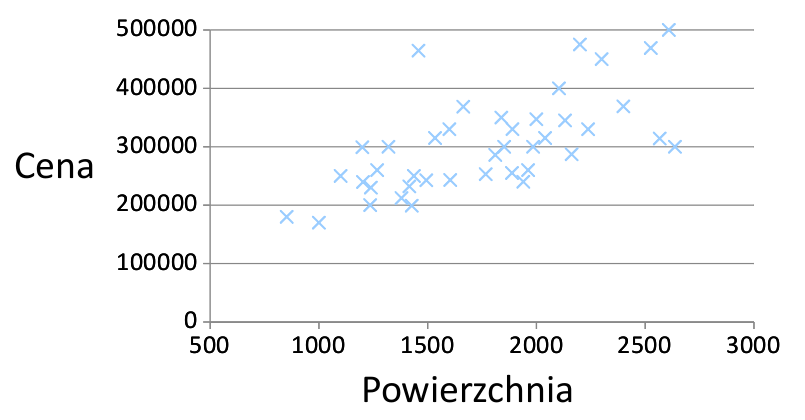
Ceny mieszkań i domów
Mamy zbiór uczący (cena mieszkań w zależności od powierzchni):
Chcemy znaleźć wielomian n-tego stopnia, który najlepiej dopasuje się do tych danych (na rysunku jest to funkcja liniowa
y = ax + b):
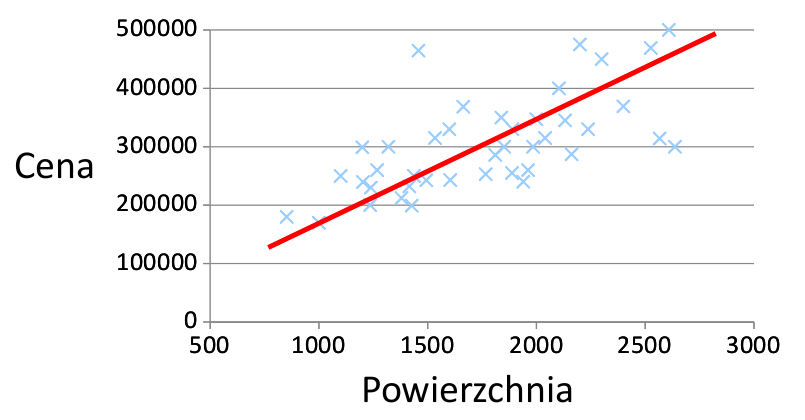
Wielomian posłuży nam później do przewidywania kolejnych elementów (ceny kolejnych mieszkań, których do tej pory nie braliśmy pod uwagę)
Sprawdziłem parametry i ceny domów w mojej okolicy i umieściłem je w tej tabelce (dane wzięte z tradycyjnego przykładu do regresji liniowej, przygotowanego w warunkach amerykańskich, stąd taka ilość sypialni). Na tej podstawie chcę przygotować model regresji liniowej i oszacować cenę mojego domu. Jak to zrobić?
| Rozmiar domu | Rozmiar działki | Liczba sypialni | Granitowe elementy w kuchni | Ulepszone łazienki? | Cena sprzedaży |
| 3529 | 9191 | 6 | 0 | 0 | 205.000 |
| 3247 | 10061 | 5 | 1 | 1 | 224.900 |
| 4032 | 10150 | 5 | 0 | 1 | 197.900 |
| 2397 | 14156 | 4 | 1 | 0 | 189.900 |
| 2200 | 9600 | 4 | 0 | 1 | 195.000 |
| 3536 | 19994 | 6 | 1 | 1 | 325.000 |
| 2983 | 9365 | 5 | 0 | 1 | 230.000 |
| 3198 | 9669 | 5 | 1 | 1 | ???? |
Na początek tworzymy odpowiedni plik Weki zgodnie z formatem, z którym się zaznajomiliśmy w poprzednim punkcie
Wskazówka 1: możemy potraktować wszystkie atrybuty jako typ numeric
Wskazówka 2: wartość nieznaną możemy w pliku .arff zapisać jako znak zapytania (?)
Wskazówka 3: jeżeli nie chcesz tworzyć pliku samodzielnie, możesz ściągnąć go stąd:
domy.arff.zip
Wczytujemy go w Wece i przeglądamy, aby upewnić się, że jest poprawny
Przechodzimy do zakładki Classify i wybieramy klasyfikator LinearRegression
Upewnij się, że w oknie Test options zaznaczona jest opcja Use training set. Uwaga! Nie powinniśmy korzystać z tej formy testowania - dlaczego? Tutaj jesteśmy zmuszeni, z uwagi na niewielki zbiór uczący…
Wciskamy Start i zapoznajemy się z wynikami. Czy je rozumiesz?
Pytanie: Jaka jest cena naszego domu? (ostatni wiersz w tabeli powyżej)
wyświetlanie predykcji możemy włączyć klikając na „More options” i zaznaczając opcję „Output predictions”
Zadania
Zadania do wykonania w Wece, na danych z paczki ściągniętej w punkcie Weka:
Wczytaj pliki cpu.arff i cpu.with.vendor.arff zawierające informacje o procesorach (nie da się tego zrobić równocześnie w jednej instancji Weki)
Czym te zbiory danych się różnią?
Na obydwu zbiorach uruchom klasyfikator LinearRegression. W test options wybierz Cross-validation: 10 Folds (co to oznacza?)
Porównaj wyniki: jaka jest różnica w skuteczności klasyfikatora? jaka jest różnica w złożoności i czytelności wyuczonego modelu?
Wczytaj plik iris.arff zawierający informacje o trzech gatunkach Irysów
Uruchom klasyfikator LinearRegression. Co się dzieje? Dlaczego?
W zakładce Preprocess wybierz z listy filtr MakeIndicator i uruchom go z domyślnymi ustawieniami. Co się zmieniło?
Ponownie uruchom klasyfikator LinearRegression. Które atrybuty okazały się istotne, a które zostały odrzucone przy uczeniu modelu?
4 Drzewa decyzyjne [20 minut]
Drzewo decyzyjne to graficzna metoda wspomagania procesu decyzyjnego, stosowana w teorii decyzji. Algorytm drzew decyzyjnych jest również stosowany w uczeniu maszynowym do pozyskiwania wiedzy na podstawie przykładów.
Przykład drzewa decyzyjnego
Przykładowe drzewo decyzyjne (dla danych z pliku weather.nominal.arff) zostało przedstawione poniżej:

Pytanie: Jak Twoim zdaniem wyglądałoby drzewo decyzyjne dla zestawu danych poniżej (podejmujemy decyzję Enjoy = yes/no na podstawie pozostałych parametrów)? Narysuj je na kartce.
| Sky | AirTemp | Humidity | Wind | Water | Forecast | Enjoy |
| sunny | warm | normal | strong | warm | same | yes |
| sunny | warm | high | strong | warm | same | yes |
| rainy | cold | high | strong | warm | change | no |
| sunny | warm | high | strong | cool | change | yes |
| cloudy | warm | normal | weak | warm | same | yes |
| cloudy | cold | high | weak | cool | same | no |
Lubiane programy TV
Poniżej znajduje się zbiór uczący dotyczący lubianych programów telewizyjnych w zależności od ich czterech właściwości:
| Przykład | Komedia | Lekarze | Prawnicy | Broń | Lubiany? |
| e1 | fałsz | prawda | fałsz | fałsz | fałsz |
| e2 | prawda | fałsz | prawda | fałsz | prawda |
| e3 | fałsz | fałsz | prawda | prawda | prawda |
| e4 | fałsz | fałsz | prawda | fałsz | fałsz |
| e5 | fałsz | fałsz | fałsz | prawda | fałsz |
| e6 | prawda | fałsz | fałsz | prawda | fałsz |
| e7 | prawda | fałsz | fałsz | fałsz | prawda |
| e8 | fałsz | prawda | prawda | prawda | prawda |
| e9 | fałsz | prawda | prawda | fałsz | fałsz |
| e10 | prawda | prawda | prawda | fałsz | prawda |
| e11 | prawda | prawda | fałsz | prawda | fałsz |
| e12 | fałsz | fałsz | fałsz | fałsz | fałsz |
| e13 | prawda | prawda | fałsz | fałsz | prawda |
-
Załaduj przykładowy zbiór danych (przedstawiony powyżej): File → Load Sample Dataset → Likes TV. W zakładce Create pojawiła się informacja o załadowanym przykładzie.
Przejdź do zakładki Solve. Tutaj będziemy tworzyć i ewaluować drzewo decyzyjne.
Jak się poruszać po narzędziu? Najważniejsze pozycje z menu:
Step → automatyczne stworzenie jednego podziału w drzewie decyzyjnym
Auto Create → automatyczne stworzenie całego drzewa (szybkość można edytować w menu Decision Tree Options → Auto Create Speed; warunki przerwania tworzenia kolejnych podziałów można ustalić w Decision Tree Options → Stopping Conditions)
Reset Graph → usunięcie stworzonego drzewa
Show Plot → wykres błędów (suma kwadratów / suma różnic) w zależności od liczby podziałów
Split Node → kliknij węzeł, aby stworzyć podział na podstawie zadanego atrybutu
Test → przetestuj drzewo zbiorem danych testowych
Test New Ex. → przetestuj drzewo dowolnym przykładem
Załadowany przykładowy plik zawiera dokładnie takie same dane jak te umieszczone w poprzednim punkcie. Korzystając z programu możesz teraz sprawdzić poprawność swoich rozwiązań na cztery pytania z poprzedniego punktu (rada: przydatne może się okazać menu Decision Tree Options → Stopping Conditions)
Wspierając się programem odpowiedz na poniższe pytania:
Jakie jest najmniejsze drzewo, które poprawnie klasyfikuje wszystkie przykłady? Czy wybieranie na każdym etapie decyzji, która daje największe information gain daje nam w rezultacie drzewo, które reprezentuje taką samą funkcję?
Podaj dwa przykłady, które nie pojawiają się w zbiorze uczącym i ustal w jaki sposób zostaną sklasyfikowane zgodnie z najmniejszym możliwym drzewem. Wyjaśnij na tych przykładach jaka tendencyjność (ang. bias) zakodowana jest drzewie.
Drzewa w Wece (w miarę możliwości czasowych)
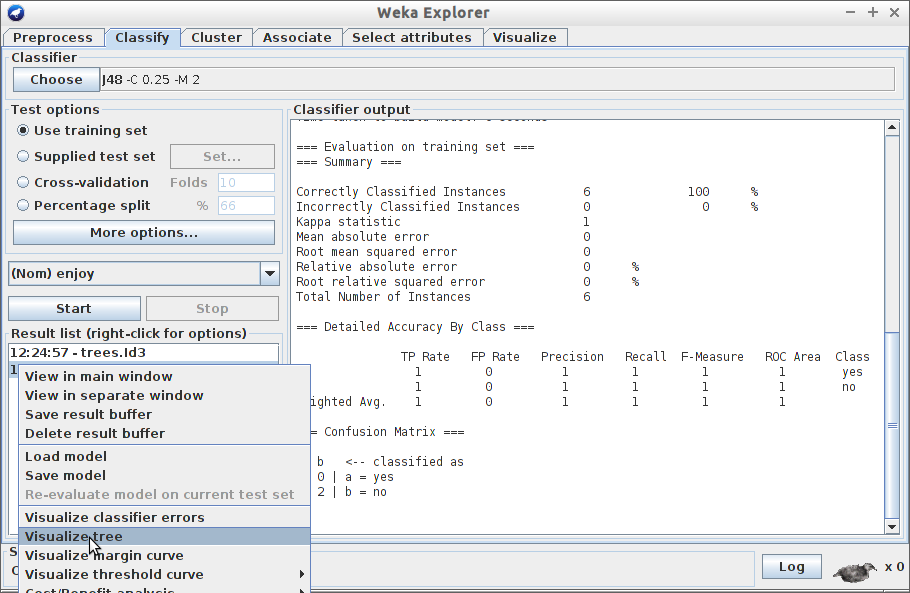
Wczytaj plik swimming.arff ze zbioru danych.
Kliknij w zakładkę Clasify.
Za pomocą przycisku
Choose wybierz klasyfikator J48
1).
Upewnij się, że w oknie Test options zaznaczona jest opcja Use training set. Uwaga! Nie powinniśmy korzystać z tej formy testowania - dlaczego? Tutaj jesteśmy zmuszeni, z uwagi na niewielki zbiór uczący…
Kliknij w przycisk Start i zapoznaj się z uzyskanymi wynikami.
Następnie zwizualizuj drzewo tak jak to pokazano poniżej:
-
5 Sieci neuronowe [15 minut]
Perceptron
Podstawową jednostką budującą sieć neuronową jest perceptron (neuron):
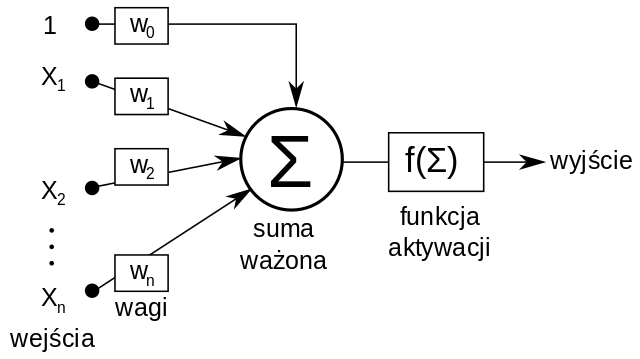
W najpopularniejszej wersji, przedstawionej na rysunku:
neuron przyjmuje jakieś wartości na wejściach (+ wartość 1, która pozwala nam dodać jakąś stałą),
mnoży te wartości przez wagi,
sumuje je ze sobą
i na koniec ustala wartość wyjściową na podstawie funkcji aktywacji.
Zadanie 1: Stwórzmy trzy takie proste neurony (na kartce, w programie graficznym, etc)! Wytyczne:
dwa wejścia binarne x1 i x2 + stała 1
funkcja aktywacji:
trzy neurony powinny reprezentować trzy operacje logiczne: x1 OR x2, x1 AND x2, x1 XOR x2
Sieć perceptronów
Mając takie perceptrony możemy je połączyć ze sobą tworząc sieć neuronową (szczegóły w materiałach do dzisiejszych zajęć), która może reprezentować bardziej skomplikowane zależności.
Zadanie 2: Otwórz narzędzie http://playground.tensorflow.org/ pozwalające na oglądanie procesu uczenia sieci neuronowej rozpoznającej dwa rodzaje (kolory) punktów w dwuwymiarowej przestrzeni.
Możesz: (a) zmienić funkcję aktywacji (Activation), liczbę warstw ukrytych i liczbę neuronów w każdej z nich, (b) wybrać jakie parametry będą dostępne na wejściu (x1, x2 reprezentują współrzędne), (c) dodać szum (noise), co sprawi, że dane będą mniej poukładane i przez to trudniejsze do rozgraniczenia.
Dla każdego z 4 dostępnych zbiorów danych spróbuj wyuczyć sieć neuronową, która NIE MA warstw ukrytych. Wypróbuj różne kombinacje parametrów wejściowych. Dla którego zbioru się nie udało? Dlaczego?
Zbuduj sieć mającą więcej warstw ukrytych (narzędzie pozwala na 6 warstw). Ile warstw będzie w porządku? Ile neuronów powinno być w każdej z warstw?
Poeksperymentuj z różnymi ustawieniami, zaobserwuj jakich wzorców uczą się neurony warstw ukrytych (możesz najechać kursorem na dany neuron i wtedy jego wzorzec zostaje powiększony) i spróbuj stworzyć sieć neuronową, która najlepiej klasyfikuje punkty ułożone w spiralę.
Zadanie 3: zagraj w kalambury z siecią neuronową: Quick, Draw!
W ramach eksperymentów spróbuj rysować INNE rzeczy niż to co jest zadane - czy sieć rozpoznaje to co rysujesz?
Po zakończeniu rozgrywki (6 haseł do narysowania) pojawia się podsumowanie - możesz kliknąć w każdy narysowany przez siebie obrazek i porównać go do tych, na których sieć została wyuczona. Czy Twój obrazek jest podobny?
6 Poprawność klasyfikacji [10 minut]
Pytania:
Załaduj plik credit-g.arff do Weki. Zawiera on dane uczące dla systemu, który na podstawie atrybutów zawartych w pliku powinien określać czy dany zestaw wartości atrybutów wskazuje na wiarygodnego klienta banku, czy też nie - czy można przyznać mu kredyt, czy jest to ryzykowne.
Przejdź do zakładki Classify i wybierz algorytm J48.
W obszarze Test options wybierz opcje Percentage split z wartością 66% Oznacza to, ze 66% danych posłuży do uczenia, a 34% do walidacji. Jakie to ma znaczenie?
Uruchom algorytm. Ile procent przypadków zostało poprawnie zaklasyfikowanych? Czy to dobry wynik?
Zmień klasyfikator na ZeroR z gałęzi rules. Jakie są wyniki?
Wybierz trzy inne klasyfikatory i je wypróbuj. Jakie dają wyniki?
Przejdź do zakładki Preprocess i zobacz jak wygląda rozkład atrybutu określającego czy danych zestaw jest dobry czy zły. Jaka byłaby skuteczność algorytmu który niezależnie od wartości atrybutów „strzelałby” że użytkownik jest wiarygodny?
Dlaczego przed przystąpieniem do klasyfikacji, warto wcześniej przyjrzeć się danym?

Chcesz wiedzieć więcej?
Film pokazujący działanie prawdziwego neuronu w mózgu: do komórki nerwowej w pierwszorzędowej korze wzrokowej kota (V1; odpowiednik pierwszej warstwy ukrytej w sieci przetwarzającej bodźce wzrokowe) podpięto elektrodę, która zbiera aktywność neuronu w zależności od pokazywanego na ekranie bodźca. Aktywność elektryczna jest przetworzona na dźwięk (neuron generuje sygnał na wyjściu kiedy pojawiają się „trzaśnięcia”). Podobnie jak pierwsza warstwa ukryta w sieci neuronowej, tak i tutaj neuron reaguje na proste kształty, by następnie przekazać informację do kolejnych warstw, które będą reagowały na bardziej konkretne układy (np. neuron rozpoznający twarz prowadzącego zajęcia).
-
Machine Learning ogólnie
Narzędzia:
Kursy Weki: jak korzystać z narzędzia, jakie ma możliwości, jak rozumieć wyniki?
-






