The ARD+ Knowledge Representation
Author: Grzegorz J. Nalepa and Igor Wojnicki
Version: Draft 2008Q3
ARD+ stands for Attribute Relationship Diagrams.
It is aimed to be as the final ARD version for the official HeKatE project (grant).

Introduction
The basic goal of rule design is to build a rule-based knowledge base from system specification.
This process is a case of knowledge engineering (KE).
In general, the KE process is different in many aspects to the classic software engineering (SE) process.
The most important difference between SE and KE is that the former tries to model how the system works, while the latter tries to capture and represent what is known about the system.
The KE approach assumes that information about how the system works can be inferred automatically from what is known about the system.
In real life the design process support (as a process of building the design) is much more important than just providing means to visualize and construct the design (which is a kind of knowledge snapshot about the system).
Another observation can be also made: designing is in fact
a knowledge-based process, where the design is often
considered a structure with procedures needed to build it (it is at least
often the case in the SE).
In case of rules, the design stage usually consists in writing actual rules, based on knowledge provided by an expert.
The rules can be expressed in a natural language, this is often the case with informal approaches such as business rules.
However, it is worth pointing out that using some kind of formalization as early as possible in the design process improves design quality significantly.
The next stage is the rule implementation.
It is usually targeted at specific rule engine.
Some examples of such engines are: CLIPS, Jess, and JBoss Rules (formerly Drools).
The rule engine enforces a strict syntax on the rule language.
Another aspect of the design - in a very broad sense - is a rule encoding, in a machine readable format.
In most cases it uses an XML-based representation.
There are some well-established standards for rule markup languages:, e.g. RuleML and notably RIF (see http://www.w3.org/2005/rules).
History and Related Documents
The original ARD method was first proposed by A. Ligęza in (ali-book) and later on developed and described by G. J. Nalepa and A. Ligęza in (gjn2005:kkio), (ali-book-springer).
It was a supportive, and potentially optional, design method for XTT (gjn2005:syssci:xtt).
It provided simple means of attribute identification for the XTT method.
The first version of ARD was applied to simple cases only, and had no practical prototype implementation.
The evolution of XTT, as well as larger complexity of systems designed with it, gave motivation for the major rework, and reformulation of ARD, which resulted in the version called ARD+.
ARD+ was defined by G. J. Nalepa and I. Wojnicki in (gjn2008flairs-ardformal) and (gjn2008aaia).
Motivation
The primary motivation for this research is an apparent lack of standard prototyping method for rules,
that would support the hierarchical and gradual design aspect covering the entire process.
Such a method should be formalized with use of some logic-based calculus in order to allow a formal analysis.
The research presented in this paper is a part of the HeKatE project,
that aims at providing an integrated and hierarchical
rule design and implementation method for rule-based systems.
The actual rule design is carried out with a flexible rule design method called XTT (eXtended Tabular Trees) (gjn2005sysscixtt).
The method introduces a structured rulebase.
So one of the main requirements for the new prototyping method should be the support for XTT.
ARD+ Method
Preliminary Concepts
The ARD+ method aims at supporting the rule designer at a very general design level, where the conceptualization of the design takes place (gjn2008flairs-ardformal), (gjn2008aaia).
It is a knowledge-based approach, based on some classic AI methods (norvig).
ARD+ covers requirements specification stage.
Its input is a general systems description in the natural language.
Its output is a model capturing knowledge about relationships among attributes describing system properties.
The model is subsequently used in the next design stage, where the actual logical design with rules is carried out.
The main concepts behind ARD+ are:
attributive logic based on the use of
attributes for denoting certain properties in a system (ali-book-springer),
ali2007flairs-granular).
functional dependency is a general relation between two or more attributes (or attribute sets), called “dependent” and “independent”; the relation is such as in order to determine the values of the dependent attributes, the values of the independent ones are needed.
graph notation provides simple, standard, yet expressive means for knowledge specification, and transformation.
visualization is the key concept in the practical design support, provided by this method.
gradual refinement is the main design approach, where the design is being specified in number of steps, each step being more detailed than the previous one.
structural transformations are formalized, with well defined syntax and semantics.
hierarchical model captures all of the subsequent design steps, with no semantic gaps; it holds knowledge about the system on the different abstraction levels
(gjn2007iwk).
knowledge-based approach provides means of the declarative model specification.
Based on these concepts, a formalization of the method is put forward in the following section.
Syntax
The ARD+ method aims at capturing relations between attributes in terms of Attributive Logic (AL)(ali-book-springer),(ali2007flairs-granular),(gjn2008ruleapps).
It is based on the use of attributes for expressing knowledge about facts regarding world under consideration.
A typical atomic formula (fact) takes the form A(o) = d, where A is an attribute, o is an object
and d is the current value of A for o.
More complex descriptions take usually the form of conjunctions of such atoms and are omnipresent in the AI literature.
Attribute
Let there be given the following, pairwise disjoint sets of symbols:
O – a set of object name symbols,
A – a set of attribute names,
D – a set of attribute values (the domains).
An attribute Ai is a function (or partial function) of the form:
Ai:o → Di.
where o ∈ O.
A generalized attribute  is a function (or partial function) of the form
is a function (or partial function) of the form Ai:o → 2Di, where 2Di is the family of all the subsets of Di, to let the attribute take more than a single value at a time.
A relaxed attribute definition, regarding a single object can be stated as:
Ai: Ai → Di.
Conceptual Attribute
A conceptual attribute A is an attribute describing some general, abstract aspect of the system
to be specified and refined.
Conceptual attribute names are capitalized, e.g.: WaterLevel.
Conceptual attributes are being finalized during the design process, into, possibly multiple, physical attributes, see Def. finalization.
Physical Attribute
A physical attribute a is an attribute describing an aspect of the system with its domain defined.
Names of physical attributes are not capitalized, e.g. theWaterLevelInTank1.
By finalization, a physical attribute origins from one or more (indirectly) conceptual attributes, see Def. finalization.
Physical attributes cannot be finalized, they are present in the final rules capturing knowledge about the system.
Property
P is a non-empty set of attributes representing knowledge about certain part of the system being designed.
Such attributes describe the property.
Simple Property
PS is a property which consists of (is described by) a single attribute.
Complex Property
PC is a property which consists of (is described by) multiple attributes.
Dependency
A dependency D is an ordered pair of properties
D1,2=[P1, P2],
where P1 is the independent property, and P2 depends functionally on P1.
Derivative
V is an ordered pair of properties, such as:
V=[P1, P2],
where P2 is derived from P1 upon transformation.
DPD
A Design Process Diagram is a triple
R=[P,D,V] where P is a set of properties, D is a set of dependencies and V is a set of derivatives.
ARD+
An Attribute Relationship Diagram
G is a pair
G=[P, D],
where P is a set of properties, and D is a set of dependencies if there is a DPD G=[P,D,V].
Diagram Restrictions
The diagram constitutes a directed graph with possible cycles.
TPH
A Transformation Process History TPH is a pair:
TPH=[P,V] if there is a DPD G=[P,D,V].
The TPH can be expressed as a directed graph with properties being nodes and derivatives being edges.
Diagram transformations are one of the core concepts in the ARD+.
They serve as a tool for diagram specification and development.
For the transformation T such as T: G1 → G2, where G1 and G2 are both diagrams, the diagram G2 carries more system related knowledge, is more specific and less abstract than the G1.
All of the transformations regard properties.
Some transformations are required to specify additional dependencies or introduce new attributes though.
A transformed diagram G2 constitutes a more detailed diagram level.
Finalization TF is a function
which transforms a DPD R into RTF by transforming a simple property PS consisting of a single conceptual attribute into a Pnew, where the attribute belonging to PS is substituted by one or more conceptual or physical attributes belonging to P;
appropriate dependencies must be transformed as well and a derivative has to be introduced.
It introduces more attributes (more knowledge) regarding particular property.
An interpretation of the substitution is, that new attributes belonging to P are more detailed and specific than attributes belonging to PS.
A split transforms a DPD R into RTS by transforming a complex property PC into some number of properties (a set) Pnew; appropriate dependencies and derivatives must be introduced.
This transformation introduces new properties and defines functional relationships among them.
Attribute Disjunction
Attribute sets belonging to each of the properties P1 … Pr have to be disjoint.
Attribute Matching
All attributes PC consists of have to belong to properties P1, … Pr.
No new attributes can be introduced for properties P1 … Pr.
Such introduction is possible through finalization only (see Def. finalization).
Attribute Pool
All attributes PC consists of have to belong to [P1, … Pr].
Dependency Inheritance
All dependencies in DPC have to be covered by dependencies in Dnew.
If a PC depends on some property Px (or some property depends on it), such a dependence must be stated (in Dnew) regarding at least one of the elements from Pnew and Px.
A number of transformations in a single design step
is limited to one per property.
It means that a property can be either split or finalized but not both.
Refactoring
During the design process some properties or attributes can be missed or treated as not important, hence not included in the diagram.
Refactoring allows to incorporate such artifacts or remove unnecessary ones.
Refactoring consists in modifying any of the existing transformations: finalization or split in a particular ARD+ diagram.
Finalization
A Finalization Refactoring consist in adding or removing an attribute, modifying a past finalization transformation.
Removing an attribute Ar results in removing it from all already defined complex properties.
If there is a simple property which regards such an attribute, it should be removed then.
The Finalization Refactoring with adding an attribute implies that at some point a split has to be performed on a property involving the new attribute.
Furthermore, appropriate dependencies between the property which consists of the introduced attribute and other properties have to be stated as well.
This constitutes a Split Refactoring
Split
In general a Split Refactoring regards:
Removing a property implies that all other properties that were split from it, even transitionally, have to be removed.
Adding a property leads to defining its dependencies, between the property and other already defined ones.
In general adjusting dependencies can be based on:
defining dependencies between the property and other existing properties at the most detailed diagram level, or
adjusting appropriate past split transformations gradually (at previous diagram levels) to take this new property into consideration.
In the first case the dependencies are defined for the most detailed diagram level only.
Since there is a hierarchical design process (see Sec. Hierarchical Model), these changes are taken into consideration at previous levels automatically.
The second case implies that the designer updates appropriate past splits in a gradual refinement process.
Stopping this process at more general level than the most detailed one, generates appropriate splits in all more detailed levels automatically.
Semantics
The semantics of ARD+ will be explained and visualized using a reworked Thermostat example, discussed in (ali-book-springer), (gjn2005:kkio).
The goal of the system is to set the temperature in the office to the given set-point, based on the current time.
A property always consists of a set of attributes, these attributes identify such a property uniquely.
The single most important concept in ARD+ is the concept of the property functional dependency.
It indicates that in order to evaluate a dependent property, all independent properties have to be evaluated first.
It means, that in order to calculate dependent property attribute values, independent properties attribute values have to be calculated first.
It indicates that a property described by Temperature depends on a property described by Time.
Identifying all possible properties and attributes in a system could be a very complex task.
Transformations (see transformation) allow to gradually refine properties, attributes and functional dependencies in the system being designed.
This process ends when all properties are described by physical attributes and all functional dependencies among properties are defined.
An example of the finalization is given in Figures:
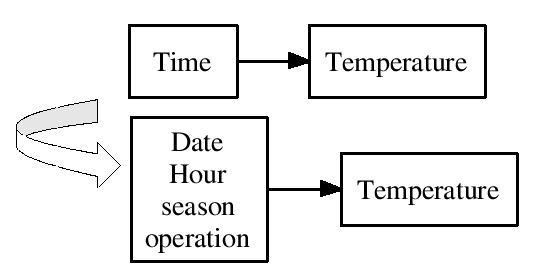
The top diagram represents the system before the finalization.
The property described by attribute Time is finalized.
As a result new attributes are introduced: Date, Hour, season, operation.
The outcome is the bottom diagram.
Semantics of this transformation is that the system property described by a conceptual attribute Time, can be more adequately described by a set of more detailed attributes: Date, Hour, season, operation, which more precisely define the meaning Time in the design.
The two latter attributes are physical ones, used in the final rule implementation.
Finalization of properties based on such attributes is not allowed.
An example of simple finalization is given in Figure:

A property described by a conceptual attribute Temperature is finalized into a property described by a single physical attribute thermostat_settings.
In other words, a general concept of temperature, represented by Temperature, is to be represented by an attribute thermostat_settings.
Another ARD+ transformation is the split.
An example is given in Figure:

The top diagram shows a situation before, and the bottom one after, the split transformation.
This split allows to refine new properties and define functional dependencies among them.
A property described by attributes: Date, Hour, season, operation, is split into two properties described by Date, Hour, and season, operation appropriately.
Furthermore there is a functional dependency defined such as season and operation depend on Date and Hour.
During the split, some of the properties can be defined as functionally independent.
An example of such a split is given in Figure:
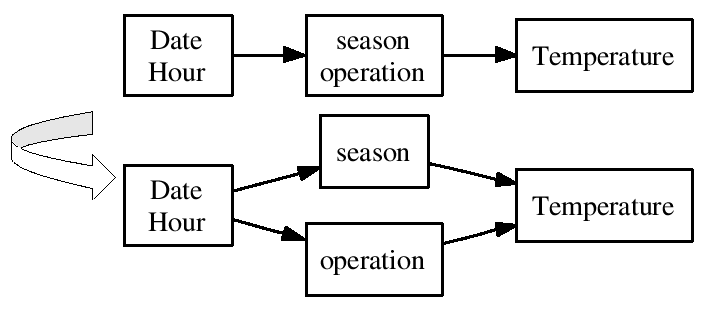
Properties described by season and operation are functionally independent.
The ARD+ design process based on transformations leads to a diagram representing properties described only by physical attributes.
An example of such a diagram is given in Figure:
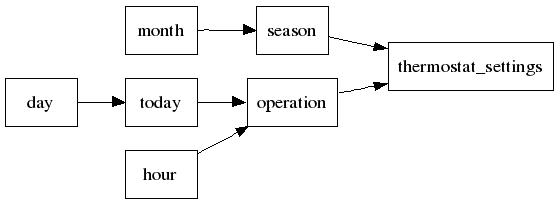
All properties of the designed system are identified.
Each of them is described by single physical attribute.
All functional dependencies are defined as well.
Each transformation creates a more detailed diagram, introducing new attributes (finalization) or defining functional dependencies (split).
These more detailed diagrams are called levels of detail or just diagram levels.
In the above examples, transitions between two subsequent levels are presented.
A complete model consists of all the levels capturing knowledge about all splits and finalizations.
Hierarchical Model
During the design process, upon splitting and finalization, the ARD+ model grows, becoming more and more specific.
This process constitutes the hierarchical model.
Consecutive levels make a hierarchy of more and more detailed diagrams describing the designed system.
The purposes of having the hierarchical model are:
gradual refinement of a designed system, and particularly,
identification where given properties come from,
ability to get back to previous diagram levels for refactoring purposes,
big picture of the designed system.
The implementation of such hierarchical model is provided through storing the lowest available, most detailed diagram level, and, additionally, information needed to recreate all of the higher levels, so called Transformation Process History, TPH for short (see Def. TPH).
The TPH captures information about changes made to properties at consecutive diagram levels.
These changes are carried out through the transformations: split or finalization.
The TPH forms a tree structure then, denoting what particular properties is split into or what attributes a particular property attribute is finalized into, according to Def. TPH.
An example TPH for the transformation is given in Figure:
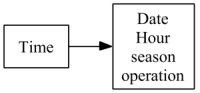 It indicates that a property described by an attribute
It indicates that a property described by an attribute Time is refined into a property described by attributes: Date, Hour, season, operation.
Another TPH example for the split transformation is given in Figure:
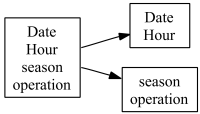 It indicates that a property described by attributes:
It indicates that a property described by attributes: Date, Hour, season, operation is refined into two properties described by: Date, Hour and season, operation attributes respectively.
Having a complete TPH and the most detailed level (namely ARD+), which constitute the DPD (according to Def. DPD) it is possible to automatically recreate any, more general, level.
Rule Prototyping Algorithm
The goal of the algorithm is to automatically build prototypes for rules from the ARD+ design (gjn2008aaia).
The targeted rule base is structured, grouping rule sets in decision tables with explicit inference control.
It is especially suitable for the XTT rule representation.
Moreover, this approach is more generic, and can be applied to any forward chaining rules.
The input of the algorithm is the most detailed ARD+ diagram, that has all of the physical attributes identified
(in fact, the algorithm can also be applied to higher level diagrams, generating rules for some parts of the system being designed).
The output is a set of rule prototypes in a very general format (atts stands for attributes):
rule: condition atts | decision atts
The algorithm is reversible, that is having a set of rules in the above format, it is possible to recreate the most detailed level of the ARD+ diagram.
In order to formulate the algorithm some basic subgraphs in the ARD+ structure are considered.
These are presented in Figures:
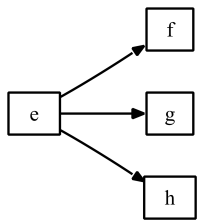

Now, considering the ARD+ semantics (functional dependencies among properties), the corresponding rule prototypes are as follows:
rule: e | f, g, h
rule: a, b, c | d
In a general case a subgraph in Figure:
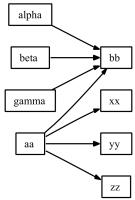
is considered.
Such a subgraph corresponds to the following rule prototype:
rule: alpha, beta, gamma, aa | bb
rule: aa | xx, yy, zz
Analyzing these cases a general prototyping algorithm has been formulated.
Assuming that a dependency between two properties is formulated as:
D(IndependentProperty,DependentProperty),
the algorithm is as follows:
choose a dependency D: D(F,T), F ≠ T, from all dependencies present in the design,
find all properties F, that T depends on:
let FT = [FTi: D(FTi,T), FTi ≠ F],
find all properties which depend on F and F alone:
let TF=[TFi: D(F,TFi), TFi ≠ T, ¬∃ TFi: (D(X,TFi), X ≠ F )]
if FT ≠ ∅, TF ≠ ∅ then generate rule prototypes:
rule: F, FT1, FT2,... | T
rule: F | TF1, TF2,...
rule: F | T, TF1, TF2,...
rule: F, FT1, FT2,... | T
rule: F | T
Rule prototypes generated by the above algorithm can be further optimized.
If there are rules with the same condition attributes they can be merged.
Similarly, if there are rules with the same decision attributes they can be merged as well.
For instance, rules like:
rule: a, b | x ; rule: a, b | y
can be merged into a single rule: rule: a, b | x, y
The practical support form the ARD+ design method, including logical modelling, visualization, and the prototyping algorithm has been implemented in the VARDA.
SPOOL









