Laboratorium 5 - Regresja Logistyczna
Lista i opis plików
Pliki oznaczone znakiem wykrzyknika ( ) należy wypełnić własnym kodem
) należy wypełnić własnym kodem
ex2.m - Skrypt Octave, który pomaga w przejściu pierwszej części laboratorium
ex2_reg.m - Skrypt Octave, który pomaga w przejściu pierwszej części laboratorium
ex2data1.txt - Training set for the �rst half of the exercise
ex2data2.txt - Training set for the second half of the exercise
mapFeature.m - Function to generate polynomial features
plotDecisionBounday.m - Function to plot classi�er's decision boundary
plotData.m - Function to plot 2D classi�cation data
sigmoid.m - funkcja sigmoidalna
costFunction.m -funkcja kosztu dla regresji logistycznej
predict.m - funkcja klasyfikująca
costFunctionReg.m - zregularyzowana funkcja kosztu dla regresji logistycznej
Wstęp
W tej części laboratorium będziemy budować model regresji logistycznej, który pozwoli przewidywać czy kandydat na studia zostanie przyjęty, czy odrzucony.
Zakładając że chcesz ustalić szanse dostania się na studia bazując na wynikach dwóch egzaminów. Masz dostępne dane historyczne w postaci wyników z poprzednich lat i związanej z nimi decyzji: przyjęty/nieprzyjęty.
Twoim zadaniem jest zbudowanie klasyfikatora, który oszacuje prawdopodobieństwo przyjęcia danego kandydata na studia w zależności od wyników dwóch egzaminów.
Wykres obrazujący dane historyczne przedstawiony jest poniżej.
Żółte kropki oznaczają odrzucone kandydatury, a czarne krzyżyki przyjętych studentów. Na osiach przedstawione są punkty z danego egzaminu.

Sigmoid Function
Funkcja hipotezy dla regresji logistycznej wygląda w sposób następujący:

Funkcja g jest funkcją sigmoidalną, określoną wzorem:

Funkcja sigmoidalna została przedstawiona na rysunku poniżej.
Uzupełnij kod pliku sigmoid.m tak aby można wyznaczała ona wartość funkcji sigmoidalnej. Możesz spróbować wyrysować funkcję sigmoidalną przy pomocy zaimplementowanej funkcji. Powinna ona wyglądać tak jak poniżej.

Uwaga Funkcja powinna działać także dla wektorów i macierzy!
Uwaga W przypadku macierzy/wektora funkcja powinna wyznaczyć wartość funkcji sigmoidalnej dla każdego elementu z osobna.
Przetestuj działanie funkcji za pomocą skryptu check.m
Cost Function
Funkcja kosztu dla regresji logistycznej wygląda następująco:

Natomiast gradient funkcji kosztu to wektor o tych samych wymiarach co wektor  , gdzie
, gdzie  -ty element (dla
-ty element (dla  ) jest zdefiniowany jako:
) jest zdefiniowany jako:

Zaimplementuj funkcję znajdującą się w pliku costFunction.m i przetestuj jej działanie za pomocą skryptów check.m i ex2.m.
Gradient Descent
Na poprzednich laboratoriach implementowaliśmy funkcję gradient descent, która krok po kroku aktualizowała współczynniki .
W tym laboratorium skorzystamy z wbudowanej w Octave funkcji fminunc.
Otwórz plik ex2.m i obejrzyj kod w okolicach linii 77-87 aby zobaczyć w jaki sposób korzysta się z tej funkcji.
Predict
Dzięki wyznaczonym parametrom jesteśmy w stanie obliczyć prawdopodobieństwo dostania się na studia. Dla przykładu prawdopodobieństwo że student, który uzyskał 45 punktów z pierwszego egzaminu i 85 punktów z drugiego zostanie przyjęty na uczelnię wynosi 0.776.
Nam zależy jednak na tym aby otrzymać jednoznaczną odpowiedź tak lub nie. W tym celu uzupełnij funkcję predict.m. Powinna ona zwracać 1, gdy wartość funkcji hipotezy jest większe bądź równe 0.5 i 0 w przeciwnym wypadku.
Przetestuj działanie funkcji za pomocą skryptu check.m
Regularized Cost Function
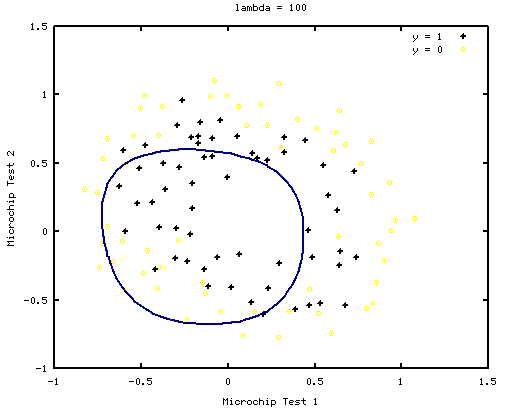
Regularyzacja pomaga zwalczyć problem tzw. overfittingu danych, który pojawia się gdy do uczenia wykorzystujemy zbyt wiele parametrów przy jednoczesnej niewielkiej ilości przykładów uczących. Overfitting skutkuje nadmiernym dopasowaniem do danych uczących i utrata pewnej generalizacji. Efektem Overfittingu jest to, że algorytm idealnie działa na zbiorze uczącym, natomiast bardzo niedokładnie klasyfikuje dane ze zbioru testowego - zobacz rysunek poniżej.

Parametrem, który pozwala na regularyzację jest parametr  . W zależności od jego wartości możemy skutecznie zlikwidować problem overfittingu. Jednak zwiększając nieodpowiedzialnie wartość tego parametru możemy doprowadzić do sytuacji, w której algorytm uczący nie będzie dobrze klasyfikował nawet danych treningowych - zobacz rysunek poniżej.
. W zależności od jego wartości możemy skutecznie zlikwidować problem overfittingu. Jednak zwiększając nieodpowiedzialnie wartość tego parametru możemy doprowadzić do sytuacji, w której algorytm uczący nie będzie dobrze klasyfikował nawet danych treningowych - zobacz rysunek poniżej.
Funkcja kosztu uwzględniająca regularyzację określona jest następującym wzorem:

Uwaga Nie normalizujemy parametru  W Octave indeksy zaczynają się od 1, dlatego parametr, który powinien zostać pominięty to theta(1). Gradient w takim wypadku przedstawia się następująco:
W Octave indeksy zaczynają się od 1, dlatego parametr, który powinien zostać pominięty to theta(1). Gradient w takim wypadku przedstawia się następująco:
Dla 

Dla 

Sprawdź swoją implementację za pomocą skryptu ex2_reg.m oraz check.m.
Uwaga Otwórz plik ex2_reg.m i przetestuj działanie algorytmu zmieniając wartość współczynnika w okolicach linii 90.



