Laboratorium 10 -- Drzewa decyzyjne
Instrukcje do laboratorium
-
W celu załadowania, wybierz 'File→Upload Notebook' w Google Colab. W przypadku lokalnej wersji, po prostu nawiguj w oknie przeglądarki do miejsca gdzie zapisany jest notebook.
Materiały
Wprowadzenie do Weki
Weka, to narzędzie opensource do data miningu.
Uruchom je wykonując w konsoli polecenie. Jeśli program nie jest zainstalowany, ściagnij go ze strony
$ weka
Jeśli program nie jest zainstalowany, ściągnij go ze strony: Weka i uruchom:
$ java -jar weka.jar
Wczytywanie i analiza danych
-
Otwórz w Gedicie plik o nazwie swimming.arff i poznaj strukturę plików uczących dla weki z danymi symbolicznymi.
Uruchom Wekę i kliknij w przycisk Explorer
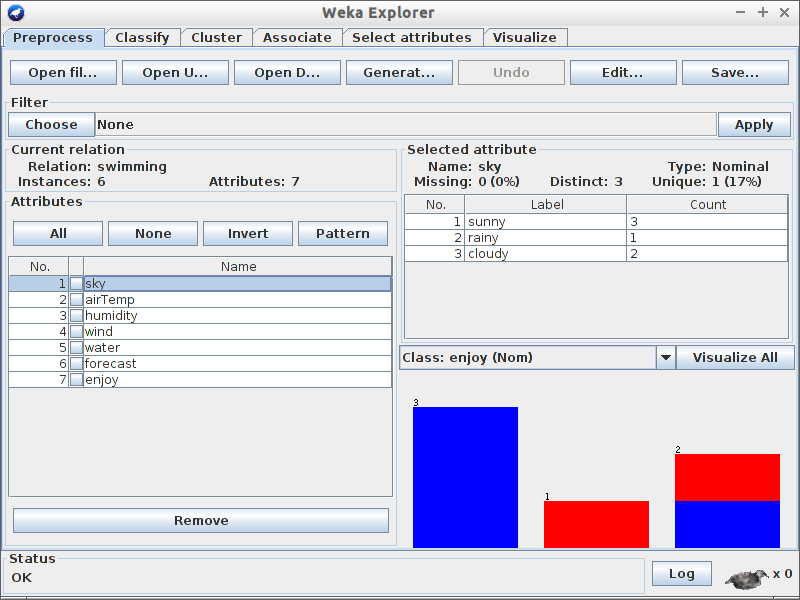
Przeanalizuj pierwszą zakładkę
GUI i odpowiedz na pytania poniżej:
Pytania
Jaki jest rozmiar zbioru uczącego?
Ile atrybutów występuje w zbiorze uczącym?
Ile jest instancji jest pozytywnych (Enjoy=yes) a ile negatywnych?
Który z atrybutów najlepiej rozdziela dane? ;)
Ile elementów ze zbioru danych ma atrybut wilgotność (humidity) ustawioną jako high?
Drzewa decyzyjne
Wczytaj plik swimming.arff ze zbioru danych
Kliknij w zakładkę Clasify
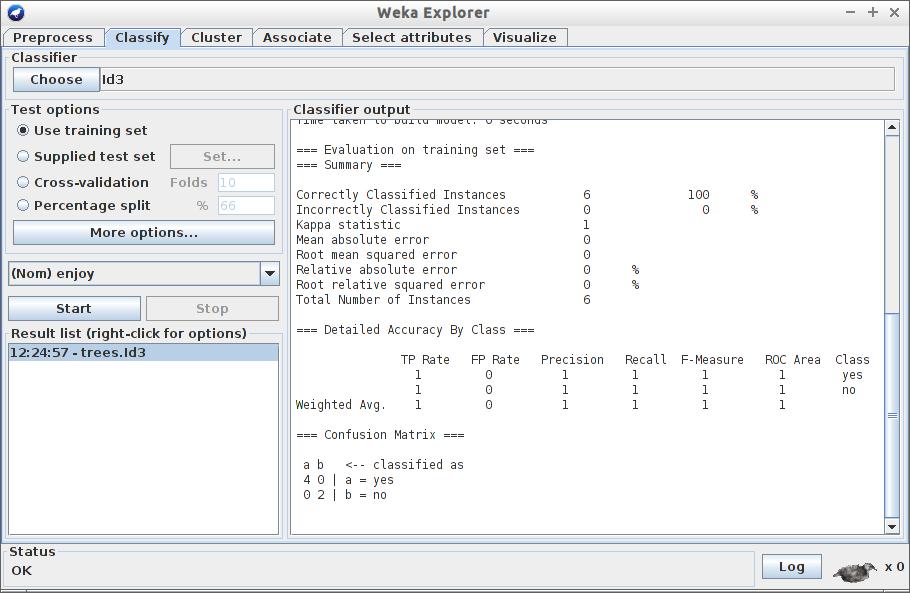
Wybierz za pomocą przycisku Choose klasyfikator Id3.
Upewnij się, że w oknie Test options zaznaczona jest opcja Use training set. Uwaga! W przyszłości nie będziemy korzystać z tej formy testowania - tutaj jesteśmy zmuszeni, z uwagi na niewielki zbiór uczący.
Kliknij w przycisk
Start. Przyjrzyj się rezultatowi. Co oznaczają wyniki?
Wybierz za pomocą przycisku
Choose klasyfikator J48 i kliknij
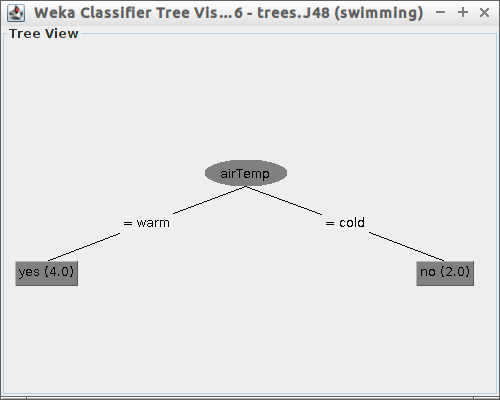
Start, następnie zwizualizuj drzewo tak jak to pokazano poniżej:
Czy drzewo wygląda tak jak je narysowałeś(aś) na początku laboratorium?
Poprawność klasyfikacji
Załaduj plik
credit-g.arff do Weki. Zawiera on dane uczące dla systemu, który na podstawie atrybutów zawartych w pliku powinien określać czy dany zestaw wartości atrybutów wskazuje na wiarygodnego klienta banku, czy też nie - czy można przyznać mu kredyt, czy jest to ryzykowne.
Przejdź do zakładki Classify i wybierz algorytm J48.
W obszarze Test options wybierz opcje Percentage split z wartością 66% Oznacza to, ze 66% danych posłuży do uczenia, a 34% do walidacji. Jakie to ma znaczenie?
Uruchom algorytm. Ile procent przypadków zostało poprawnie zaklasyfikowanych? Czy to dobry wynik?
Zmień klasyfikator na ZeroR z gałęzi rules. Jakie są wyniki?
Wypróbuj inne klasyfikatory. Jakie dają wyniki?
Przejdź do zakładki Preprocess i zobacz jak wygląda rozkład atrybutu określającego czy danych zestaw jest dobry czy zły. Jaka byłaby skuteczność algorytmu który niezależnie od wartości atrybutów „strzelałby” że użytkownik jest wiarygodny?
Dlaczego przed przystąpieniem do klasyfikacji, warto wcześniej przyjrzeć się danym? ;P
User Classifier
Zbuduj drzewo z wykorzystaniem klasyfikatora „User Classifier” dla danych z pliku (użyj PPM do „domknięcia” wielokąta):
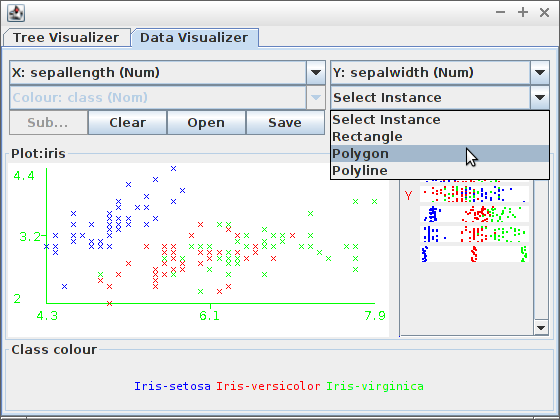
Zaakceptuj zbudowane drzewo i zobacz wyniki:
Materiały





