Evaluation of knowledge in semantic applications
Since we are considering evaluation of knowledge in distributed knowledge base systems based on semantic wikis we need to look at problems arising in all components of the system.
General problems worthy of consideration in case of knowledge evaluation, which further increase in case of the distributed knowledge bases are:
Consistency:
Contradictory conclusions can not be inferred from valid facts
This includes the detection of ambiguous or ambivalent rules, as well as the system
determinism for inference strategy.
Completeness:
the system finds a solution
interpreted as a Cartesian product of input
Conciseness:
This means there are no unnecessary redundant informations in knowledge base that may influence system optimality.
The problem consists of: searching for repetitions (that means the same, logically
identical and unused rules) for rules that can be reduced by the elimination of unnecessary attributes.
Problems associated with ontologies contained in the base (or bases based ontologies):
Circularity - Circularity of links between taxonomy classes)
Deficiency - Insufficient classification of concepts
Expandability / Sensitiveness – Measuring the costs of adding a new package of knowledge to the base and impact of adding a small information on the entire knowledge base.
Of course, we need to consider issues arising from the use of wiki as a base interface to the knowledge base.
The classic wiki problems are dead links and unreachable pages that are not connected with the remaining wiki content. ( „orphan pages”). In addition, circular dependency may occur(A page contains a link for the information X to page B, which has a link for the information X to page A). In the classical wiki this problem could not be resolved automatically. However, in semantic systems page contains information capable of being interpreted by the computer, so you can easily look for these links and correct them.
The semantic wiki page consists of two parts: the classical representation of knowledge based on text and multimedia, and semantic stored using ontologies which is the formal knowledge base. Ontologies semantically describing pages, considered as a separate knowledge bases co-operating with each other,will enable the verification of knowledge by checking the consistency and completeness.
It is worth to also consider problems of connections between different wiki systems,
eg. relationship between ontology domains on this wikis. Again, there is also problem with circular links, but in this case, the knowledge base of one wiki is insufficient to determine the problem.
Examining wiki’s consistency
Wiki as a knowledge base is vulnerable to any inaccuracy in knowledge due to
social, distributed nature of the system. Packages of knowledge are added, modified by many users, so it's important to test the consistency of knowledge. As far as we are considering single wiki page as a separate knowledge base, the easiest way to examine the consistency would be searching contradictory facts and rules. Facts e.g. stored in the RDF (Resource Description Framework), can be easily viewed, parsed and looked for contradictions. The real problem, is however to select correct fact from among conflicting, due to the continued development of the knowledge base through changes made by users, we do not know which change is correct. The only clue could be other already verified facts or rules.
Examining wiki’s completeness
Examining completeness of knowledge on the wiki has to take into account not only one side (knowledge base), but the wiki as a whole. This is a difficult topic to research and evaluate, because we often do not know what information to expect in the knowledge base with respect to specific ontology. However, if we know what knowledge has to be included, it can easily to find the missing part of knowledge.
Examining wiki’s conciseness
Because of optimization it is undesirable for knowledge base to have repeating facts and rules. Facts and rules that are more general than previous entries could be proper information but it could happened that we want more specific informations. So it is difficult to determine which of two redundant rules is valid.
Problems, anomalies arising from the open nature of wikis, with collaborative knowledge base creation.
Heterogeneity of concepts.
Uselessness of knowledge.
Oscillating knowledge.
Heterogeneity of concepts is the problem of level of detail in the description of the concept in different ontologies. Difference in the level of detail between ontologies makes impossible to communicate and exchange knowledge. Because of that different ways to compare ontologies are implemented.
Measuring the usefulness of knowledge has always been a major problem of knowledge engineers. However, in the case of wikis, using the possibility of interference in party members, there are ways to evaluate the usefulness of knowledge. The simplest way may be to grant privilege to evaluate knowledge to all registered users. Of course, system should be more sophisticated through, for example, the weight of votes for different users. By publishing a lot of pages in a given category, the votes would have a higher weight from the beginner user.
Oscillating knowledge is a unique problem for the knowledge systems based on users community who interfere with the content of that knowledge. In the case of traditional Wiki appears the phenomenon called „edit war - constant editing one page by multiple users, „fighting” with each other about the content of the page.
Now we will look at different ways to cope with this problems and evaluate knowledge.
There are many interesting articles about this challenge, we will provide a closer look at some of those ideas.
Α Survey of Ontology Evaluation Techniques[2]
Various approaches to the evaluation of ontologies have been considered in the literature, depending on what kind of ontologies are being evaluated and for what purpose. Broadly speaking, most evaluation approaches fall into one of the following categories:
those based on comparing the ontology to a “golden standard”;
those based on using the ontology in an application and evaluating the results;
those involving comparisons with a source of data (e.g. a collection of documents) about the domain to be covered by the ontology;
those where evaluation is done by humans who try to assess how well the ontology meets a set of predefined criteria, standards, requirements, etc.
While evaluating ontologies we should take a level based approach. The individual levels have
been defined variously by different authors, but these various definitions tend to be broadly similar and usually involve the following levels:
Lexical, vocabulary, or data layer.
Hierarchy or taxonomy.
Other semantic relations.
Context or application level.
Syntactic level.
Structure, architecture, design.
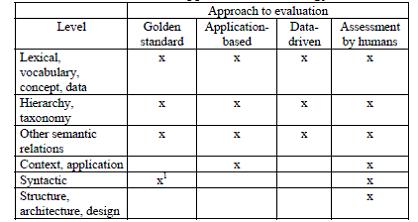
Table with approaches to ontology evaluation[1]
Ontology selection[3]
To provide high quality of knowledge in system we must first of all use proper ontology. To select this ontology methods of evaluation are needed. Ontology selection and evaluation are incredible important and it is worthy to explore how these two tasks relate. Ontology evaluation approaches are unevenly distributed in two major categories. On one hand, a few principled approaches exist that define a set of well-studied, high level ontology criteria to be manually assessed (e.g., OntoClean, Ontometric). On the other hand, the use of ontology evaluation in the context of ontology learning has lead to the development of automatic approaches that cover different evaluation perspectives and levels. Evaluation levels refer to the aspects of the ontology that are evaluated (e.g., labels, conceptual structure). Perspectives are defined by what is considered to be a good “quality” ontology. In an application specific ontology evaluation the quality of an ontology is directly proportional to the performance of an application that uses it. In a Gold Standard based ontology evaluation the quality of the ontology is expressed by its similarity to a manually built Gold Standard ontology. In a corpus coverage scenario the quality of the ontology is represented by its appropriateness to cover the topic of a corpus.
We define ontology selection as the process that allows identifying one or more ontologies or ontology modules that satisfy certain criteria. The actual process of checking whether an ontology satisfies ceratin criteria is, in essence, an ontology evaluation task.
We distinguish the following elements that characterize the ontology selection process:
The information need.
The selection criteria.
The Ontology library.
The output.
Ontology libraries are crucial to facilitating ontology reuse. Several ontology library systems have been developed during the last years. However, a comparison between the libraries described by an earlier survey and those developed in the last two years (e.g., Swoogle, OntoSelect, OntoKhoj) shows an important change in the role and characteristics of these systems.
We identified three categories of approaches that select ontologies according to their popularity, the richness of semantic data that is provided and topic coverage.
Popularity - select the “most popular” (i.e., well established) ontologies from an ontology collection. They rely on the assumption that ontologies that are referenced (i.e., imported, extended, instantiated) by many ontologies are the most popular
(a higher weight is given to ontologies that themselves are referenced by other popular ontologies). These approaches rely on metrics that take into account solely the links between different ontologies. It is quite similar to way how present search engines work and in fact often modified PageRank algorithm is used. Currently there are three approaches to this task(OntoKhoj,Swoogle,OntoSelect).
The richness of semantic data - estimate the richness of knowledge that they express. When approximating this aspect, most approaches investigate the structure of the ontology. The ActiveRank algorithm is the only selection algorithm that has been developed independently from an ontology library. ActiveRank combines a set of ontology structure based metrics when ranking ontologies. To determine the richness of the conceptualization offered by the ontology they use the Density Measure(DEM) metric. This measure indicates how well a given concept is defined in the ontology by summing up the number of its subclasses, superclasses, siblings, instances and relations.
Topic coverage - ontologies can be ranked based on the level to which they cover a certain topic. To determine this, most approaches consider the labels of ontology concepts and compare them to a set of query terms that represent the domain. The Class Match Measure (CMM) of ActiveRank denotes how well an ontology covers a set of query terms. It is computed as the number of concepts in each ontology whose label either exactly or partially matches the query terms.
An Evaluation of Knowledge Base Systems for Large OWL Datasets using LUBM [4]
Lehigh University Benchmark (LUBM) has been developed by a group of scientists from Leigh University. he benchmark is intended to evaluate knowledge base systems with respect to extensional queries over a large dataset that commits to a single realistic ontology. LUBM features an OWL ontology modelling university domain, synthetic OWL data generation that can scale to an arbitrary size, fourteen test queries representing a variety of properties, and a set of performance metrics. Generally, there are two basic requirements for such systems. First, the enormous amount of data means that scalability and efficiency become crucial issues. Second, the system must provide sufficient reasoning capabilities to support the semantic requirements of the application. However, increased reasoning capability usually means an increase in query response time as well. An important question is how well existing systems support these conflicting requirements. Furthermore, different applications may place emphasis on different requirements.
The ontology used in the benchmark is called Univ-Bench. Univ-Bench describes universities
and departments and the activities that occur at them. The ontology is in OWL Lite, the simplest sublanguage of OWL.
LUBM’s test data are extensional data created over the Univ-Bench ontology. LUBM introduced a method of synthetic data generation. This serves multiple purposes. This allows to control the selectivity and output size of each test query. Data generation is carried out by the Univ-Bench artificial data generator (UBA). LUBM currently offers fourteen test queries, one more than when it was originally developed. While creating those tests following factors have been taken into account:
Input size - the proportion of the class instances involved in the query to the total class instances in the benchmark data.
Selectivity - the estimated proportion of the class instances involved in the query that satisfy the query criteria.
Complexity – there are many classes and properties indicating the complexity, the real degree of complexity may vary by systems and schemata.
Assumed hierarchy information – this indicates whether information of class or property hierarchy position is necessary to inference correct answer.
Assumed logical inference - this indicates whether logical inference is necessary to achieve complete answer.
After defining tests, benchmark needs performance metrics to operate on them. LUBM uses following metrics:
Load Time - measure the load time as the stand alone elapsed time for storing the specified
dataset to the system. This also counts the time spent in any processing of the ontology and
source files, such as parsing and reasoning.
Repository Size - the consequent size of the repository after loading the specified benchmark
data into the system.
Query Response Time - query response time is measured based on the process used in database benchmarks. To account for caching, each query is executed for ten times consecutively and the average time is computed.
Query Completeness & Soundness - in logic, an inference
procedure is complete if it can find a proof for any sentence that is entailed by
the knowledge base. With respect to queries, LUBM say a system is complete if it generates
all answers that are entailed by the knowledge base, where each answer is a binding
of the query variables that results in an entailed sentence.
Combined Metric (CM) - the metric to measure query response time ad query answer completeness in combination is needed so as to better appreciate the overall performance of a system and the potential trade off between the query response time and inference capability. At the same time, scientists working on LUBM project have realized that this is a challenging issue. Their metric is:
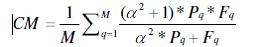
Where:
M – Total number of test queries.
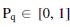 query performance metric.
query performance metric.
F – is a F-Measure
Knowledge base systems used in benchmark:
Sesame
OWLJessKB
DLDB-OWL
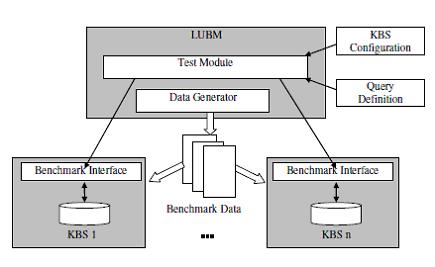
Benchmarking Architecture[3]
Task-based evaluation of Semantic Web[5]
There are many algorithms that solve a variety of tasks by harvesting the Semantic Web, i.e., by dynamically selecting and exploring a multitude of online ontologies. Authors hypothesis is that the performance of such novel algorithms implicitly provides an insight into the quality of the used ontologies and thus opens the way to a task-based evaluation of the Semantic Web. Three tasks used in this article are:
Such a task-based evaluation of the Semantic Web complements current efforts for evaluating (online) ontologies. Ontology evaluation has been a core research topic from the early stages of the Semantic Web.
Ontology matching
Ontology matching is the task of determining the relations that hold between the entities of two ontologies. Authors proposed a new paradigm to ontology matching which relies on harvesting the Semantic Web: it derives semantic mappings by dynamically selecting, exploiting, and combining multiple and heterogeneous online ontologies.The matcher will 1) identify (at run-time, during matching) online ontologies that can provide information about how concepts inter-relate and then 2) combine this information to infer the mapping. There are two strategies used while matching,in strategy S1 the mapping can be provided by a single ontology, In strategy S2 a mapping can be derived by reasoning with information spread over several ontologies.
During this experiment two large, real life thesauri were used. The United Nations Food and Agriculture Organization (FAO)’s AGROVOC thesaurus, and The United States National Agricultural Library (NAL) Agricultural thesaurus NALT. The matching process performed by using strategy S1 resulted in a total of 6687 mappings obtained by dynamically selecting, exploring and combining 226 online ontologies. Authors concluded that online ontologies are useful to solve real life matching tasks. Indeed, if combined appropriately, they can
provide a large amount of mappings between the matched ontologies. More interesting problem is the quality of online ontologies.
To assess the quality of the knowledge provided by online ontologies manual assessments of mapping were performed. Authors used six members of their lab working in the area of the Semantic Web, and performed two parallel evaluations of the sample mappings. For sample of 1000 mappings precision values: 63% and 69% for the two groups.
Folksonomy tagspace enrichment
Folksonomies (i.e., lightweight structures that emerge from the tag space) are easy to create, they only weakly support content retrieval since they are agnostic to the relations between their tags: a search for mammal ignores all resources that are not tagged with this specific word, even if they are tagged with semantically related terms such as lion, cow, cat. There is the idea of using some semantic enrichment algorithm which complies with the paradigm of harvesting the Semantic Web by dynamically exploring and combining multiple online ontologies to derive explicit relations among implicitly interrelated tags. Given a set of implicitly related tags, the prototype identifies subsumption and disjointness relations between them and constructs a semantic structure based on these relations. The general conclusion of the study is that while online
ontologies can indeed be used to semantically enrich folksonomies, some of their
characteristics hamper the process.
Word sense disambiguation
The goal of the Word Sense Disambiguation (WSD) task is to identify the appropriate
sense of a word in a given context. Usually this task involves identifying
a set of possible senses and then filtering out the right one based on some similarity
algorithms.
There is a novel, unsupervised, multi-ontology WSD method [14] which 1)
relies on dynamically identified online ontologies as sources for candidate word
senses and 2) employs algorithms that combine information available both on
the Semantic Web and the Web in order to compute semantic measures. Provided example showed that online ontologies provide a good source for word. A major benefit of relying on multiple, online ontologies is that a much larger set of keyword senses can be discovered than in cases when few, predefined resources are used.
The major conclusion that Authors derive based on the content of our observations is that online ontologies have a great potential for being used in combination to solve a variety of real life tasks. Indeed, combining knowledge from multiple ontologies lead to a broad range of high quality mappings and to more word sense definitions during WSD
Finding and ranking knowledge[6]
Navigating Semantic Web on the Web is difficult due to the paucity of explicit hyperlinks beyond the namespaces in URIrefs and the few inter-document links like rdfs:seeAlso and owl:imports. Authors proposed in this paper a novel Semantic Web navigation model providing additional navigation paths through Swoogle’s search services such as the Ontology Dictionary. Using
this model, algorithms for ranking the importance of Semantic Web objects at three levels of granularity: documents, terms and RDF graphs had been developed.
Simplifying the Semantic
Web navigation model by generalizing navigational paths into three types of document
level paths (see below) and then applying link analysis based ranking methods with
‘rational’ surfing behaviour introduced three relation types:
An extension (EX) relation holds between two SWDs(Semantic Web Document) when one defines a term using terms defined by another. EX generalizes the defines SWT(Semantic Web Term)-SWD relations, the extends SWT-SWT relations, and the official Onto SWT-SWD relation. For example, an SWD d1 EX another SWD d2 when d1 defines a class t1, which is the subclass of a classt2, and t2’s official ontology is d2.
A use-term (TM) relation holds between two SWDs when one uses a term defined by another. TM generalizes the uses and populates SWT-SWD relations, and the official Onto SWT-SWD relation. For example, an SWD d1 TM another SWD d2 when d1 uses a resource t as class, and t’s official ontology is d2.
An import (IM) relation holds when one SWD imports, directly or transitively, another SWD, and it corresponds to the imports SWD-SWD relation.
Swoogle’s OntoRank is based on the rational surfer model which emulates an agent’s navigation behaviour at the document level. Like the random surfer model, an agent either follows a link in an SWD to another or jumps to a new random SWD with a constant probability 1 - d. It is ‘rational’ because it emulates agents’ navigation on the Semantic Web, i.e., agents follow links in a SWD with non-uniform probability according to link semantics. When encountering an SWD A, agents will (transitively) import the “official” ontologies that define the classes and properties referenced by A. Let link(A; l;B) be the semantic link from an SWD A to another SWD B with tag l; linkto(A) be a set of SWDs link directly to the SWD A; weight(l) be a user specified navigation preference on semantic links with type l, i.e., TM and EX; OTC(A) be a set of SWDs that (transitively) IM or EX A as ontology; f(x; y) and wPR(x) be two intermediate functions.
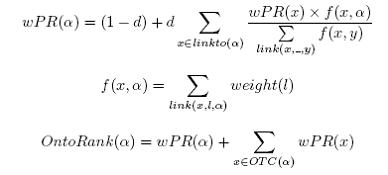
Ranking ontologies at the term level is also important because SWTs defined in the same SWO are instantiated in quite different frequency. For example, owl:versionInfo is far less used than owl:Class. Users, therefore, may want to partition ontologies and then import a part of an SWO. These observations lead to the “Do It Yourself” strategy i.e., users can customize ontologies by assembling relevant terms from popular ontologies without importing them completely.
Swoogle uses TermRank to sort SWTs by their popularity, which can be simply measured
by the number of SWDs using/populating an SWT. This naive approach, however, ignores users’ rational behaviour in accessing SWDs, i.e., users access SWDs with nonuniform probability. Therefore, TermRank is computed by totaling each SWD’s contribution.
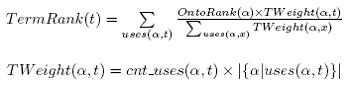
References:
Baumeister, J., & Nalepa, G. J. (2009). Verification of Distributed Knowledge in Semantic Knowledge Wikis.
-
Marta Sabou, V. Lopez, Enrico Motta, Victoria Uren,
Ontology Selection:Ontology Evaluation on the Real Semantic Web,
eon2006.pdf Yuanbo Guo, Zhengxiang Pan, and Jeff Heflin,
An Evaluation of Knowledge Base Systems for Large OWL Datasets,
guo04d.pdf Marta Sabou1, Jorge Gracia, Sofia Angeletou,Mathieu d’Aquin, and Enrico Motta,
Evaluating the Semantic Web: A Task-based Approach,
421.pdf Li Ding, Rong Pan, Tim Finin, Anupam Joshi, Yun Peng,, Pranam Kolari,
Finding and Ranking Knowledge on the Semantic Web,
197.pdf





