To jest stara wersja strony!
Opis
SemWeb_RDFize
Spotkania
20090319
Projekt
Introduction to the Semantic Web
The World Wide Web is the largest single information resource humanity has ever produced. Unfortunately, despite its dependence on computers to operate at all, most of the information is only understandable by humans and not by computers. While computers can use the syntax of HTML documents to display them to you in a browser, Web computers can't understand the content—the semantics.
The Semantic Web is Tim Berners-Lee's vision of the future of the Web. Although the dream is not yet realized, enough building blocks are now in place to enable you to take advantage of several Semantic Web technologies on your Web site, including RDF, OWL and SPARQL. The goal of the Semantic Web is to expose the vast information resource of the Web as data that computers can automatically interpret.
The Web was originally all about documents. The simple act of clicking on a link in your Web browser triggers your browser to ask a Web server to send you a document, which it then displays to you. The document might be your calendar for the next seven days, or it might be an e-mail from a friend. The Web browser doesn't really care; it just follows its internal rules for displaying the page. It's up to you to understand the information on the page.
Structuring data adds value to that data. With consistent structure, it can be used in more ways. You can see the demand for structured data today in the proliferation of APIs that have sprung up around Web sites as a part of the Web 2.0 trend—an API is structured data, and structured data from a variety of sources is what powers mashups. The idea behind mashups is that data is pulled from various sources on the Web and, when combined and displayed in a unified manner, this combination of elements adds value over and above the source information alone.
The individual APIs that everyone is busy building are to solve the exact same problem that the Semantic Web is intended to address: Expose the content of the Web as data and then combine disparate data sources in different ways to build new value. Rather than build and maintain your own API, you can build your Web site to take full advantage of the Semantic Web infrastructure which is already in place. If your Web site is your API, you can reduce the overall development and maintenance. Similarly, rather than build custom solutions for every Web site you want to pull data from, you can implement one solution based on Semantic Web technologies and have it work interchangeably across many Web sites—including Web sites you weren't even aware of before you began development.
Semantic Annotation
Here is what we consider semantic annotations:
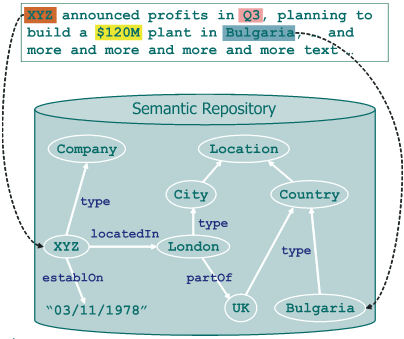
The information about what entities appear in a text and where they do. Actually, the references from the text to a semantic repository, containing further knowledge.
Annotation
'Annotation' has two meanings in contemporary English (according to WordNet, similar in Merriam-Webster):
note, annotation, notation: a comment (usually added to a text);
annotation, annotating – the act of adding notes.
In linguistics (and particularly in computational linguistics) an annotation is considered a formal note added to a specific part of the text. There are a number of alternatives regarding the organization, structuring, and preservation of annotations. For instance, all the markup languages (HTML, SGML, XML, etc.) can be considered as schemata for embedded annotation. Contrary there are models suggesting that the annotations should be kept detached (non-embedded) from the content, i.e.
Semantic Annotations
We refer to semantic annotation at the same time as (i) a sort of meta-data and (ii) the process of generation of such meta-data.
While there could be an argument with respect to the name (it could well be „Entity annotation”) its nature is quite unambiguous: the named entities in the text are recognized and identified. The result is formally recorded and associated with the place in the text where the entity has been mentioned. The identity of the entity is „verbalized” via URIs which means that those can be easily linked to their descriptions within a semantic repository, as demonstrated below.
Although redundant, in accordance with the good NE recongnition tradition in the IE community, the types of the entities are also explicitly indicated via URIs to the respective (most specific) classes in the ontology.
Named Entities
Named entities (NE) are considered: people, organizations, locations, and others referred by name. Apples and bicycles are not considered NE, because those are not typically referred by name.
Within a wider interpretation, NE can be considered also some scalar values (numbers, amounts of money, dates) and addresses.
Couple of principle comments:
Named entities and words have different semantics – the former denote particulars (individuals), the latter – universals (concepts, classes, relations, attributes).
While the words require handling of lexical semantics and common sense, the understanding and managing of named entities requires more specific world knowledge.
What about words?
Words can also be formally marked up. One of the typical approaches is to annotate the respective word with some sort of a designator of the word sense used in the specific case. For instance, a designator could be „link-v2”, meaning that the second meaning (according to some register) of the word „link” is taken as a verb (it could well serve as a noun).
There are number of tough issues relared to the word meanings:
Word Sense Disambiguation (WSD) - the process of guessing the meaning of the word used in this specific context. This is a very tough problem.
Formal definition of the meanings. While the first step is to distinguish and guess the sense, in which the word has been used, the next one is to define the meaning formally. There is no easy way to define „apple”, „know”, „synergy”, and even „house”, if you need a definition that helps one to answer „what is a house?”, „is this a house?”, etc.
RDFa
Marking up content with RDFa
The following block of HTML shows a review of a video game.
HTML:
<p><strong>Blast 'Em Up Review</strong></p>
<p>by Bob Smith</p>
<p>March 20, 2009</p>
<p>This is a great game. I enjoyed it from the
opening battle to the final showdown with
the evil aliens.</p>
<p>4.5 out of 5 stars</p>
Rendered HTML in browser:
Blast 'Em Up Review
by Bob Smith
March 20, 2009
This is a great game. I enjoyed it from the opening battle to the final showdown with the evil aliens.
4.5 out of 5 stars
To understand how to use RDFa, think about two concepts: entities (for example, a review) and properties of those entities (for example, the author of the review, the date of the review, the review itself, and the rating).
This is the HTML with RDFa markup:
<div xmlns:v="http://rdf.data-vocabulary.org/#" typeof="v:Review">
<p><strong><span property="v:itemReviewed">Blast 'Em Up</span>Review</strong></p>
<p>by <span property="v:reviewer">Bob Smith</span></p>
<p><span property="v:dtReviewed">March 20, 2009</span></p>
<p><span property="v:description">This is a great game. I enjoyed it from the opening battle to the final showdown with the evil aliens.</span></p>
<p><span property="v:rating">4.5</span> out of 5 stars</p>
</div>
This example contains three important properties:
xmlns. Occurs in the first line, and specifies the namespace where the vocabulary (a list of entities and their components) is specified. You can use the xmlns:v="http://rdf.data-vocabulary.org/# namespace declaration any time you are marking up pages for people, review, product, or place data. Be sure to use a trailing slash and # (xmlns:v="http://rdf.data-vocabulary.org/#" ).
typeof: Occurs in the first line of this
HTML block, and defines entities. Since this example contains a review, the entity is of type Review.
property: Used to label the properties of an entity. In the example, there are many properties of the review that are labeled: the reviewer, date of the review (dtReviewed), the review itself (description), and the rating (rating).
These three properties can be used in any HTML tags that open and close (div and span are two common choices). To mark up content using RDFa:
Begin with a namespace declaration using xmlns
Specify the type of content that is being marked up using typeof
Label the properties using property.
Relationships between entities in RDFa
In the example below, we describe two entities: a review and a person.
HTML:
<p><strong>Blast 'Em Up Review</p>
<p>by Bob Smith, Senior Editor at ACME Reviews</p>
<p>This is a great game. I enjoyed it from the opening battle to the final showdown with the evil aliens.</p>
<p>4.5 out of 5 stars</p>
Rendered HTML in browser:
Blast 'Em Up Review
by Bob Smith, Senior Editor at ACME Reviews
This is a great game. I enjoyed it from the opening battle to the final showdown with the evil aliens.
4.5 out of 5 stars
In this example, the relationship between the two entities is that the person is the reviewer who created the review. The review and person entities each have their own set of properties. The properties of the person are their name (Bob Smith), job title (Senior Editor), and company (ACME Reviews). The properties of the review are the reviewer (an entity), the review itself, and the rating (4.5).
To convey the relationship between the review and the person, we use the rel property. Here is how this example looks with RDFa markup:
<div xmlns:v="http://rdf.data-vocabulary.org/#" typeof="v:Review">
<p><strong><span property="v:itemReviewed">Blast 'Em Up</span>
Review</strong><p>
<p>by <span rel="v:reviewer">
<span typeof="v:Person">
<span property="v:name">Bob Smith</span>, <span property="v:title">Senior
Editor</span> at <span property="v:affiliation">ACME Reviews</span>
</span>
</span></p>
<p><span property="v:description">This is a great game. I enjoyed
it from the opening battle to the final showdown with the evil aliens.</span></p>
<p><span property="v:rating">4.5</span> out of 5 stars</span></p>
</div>
The following two lines define the relationship between the two entities:
<p>by <span rel="v:reviewer">
<span typeof="v:Person">
Here, by using rel instead of property, we define a relationship between the review and the person, namely that the writer of the review (the „reviewer”) is an entity (Person), with its own properties such as name, title, and org.
„rel” without „typeof”
The final concept to understand in order to mark up your content with RDFa is that rel can exist without an explicitly labeled typeof. In these cases, the entity is implicitly defined.
HTML Rendered HTML in browser
HTML:
<p><img src="www.example.com/bobsmith.jpg" /></p>
<p><strong>Bob Smith</strong></p>
<p>Senior editor at ACME Reviews</p>
<p>200 Main St</p>
<p>Desertville, AZ 12345</p>
Rendered HTML in browser:
Bob Smith
Senior editor at ACME Reviews
200 Main St
Desertville, AZ 12345
Here is the HTML with RDFa markup:
<div xmlns:v="http://rdf.data-vocabulary.org/#" typeof="v:Person">
<span rel="v:photo">
<img src="www.example.com/bobsmith.jpg" />
</span>
<p><span property="v:name"><strong>Bob Smith</strong></span></p>
<p><span property="v:title">Senior Editor</span> at <span property="v:affiliation">ACME Reviews</span></span></p>
<span rel="v:address">
<p><span property="v:street-address">200 Main St</span></p>
<p><span property="v:locality">Desertville</span></p>
<p><span property="v:region">AZ</span> </p>
<p><span property="v:postcode">12345</span></p>
</span>
</div>
In this example there are two implicitly defined entities: the person's photo and their address. Since the address property always relates to an entity of type address, there is no need to explicitly include a line with typeof=„v:Address”. Similarly, a photo always relates to a URL pointing to an image, so there is no need to explicitly define a typeof property.
Sprawozdanie
Prezentacja
Materiały
